from scipy.optimize import minimize
import matplotlib.pyplot as plt
import numpy as np
from scipy.special import expit
def load(filepath: str)->np.ndarray:
dataset = []
f = open(filepath)
for line in f:
dataset.append(line.strip().split(','))
return np.asfarray(dataset)
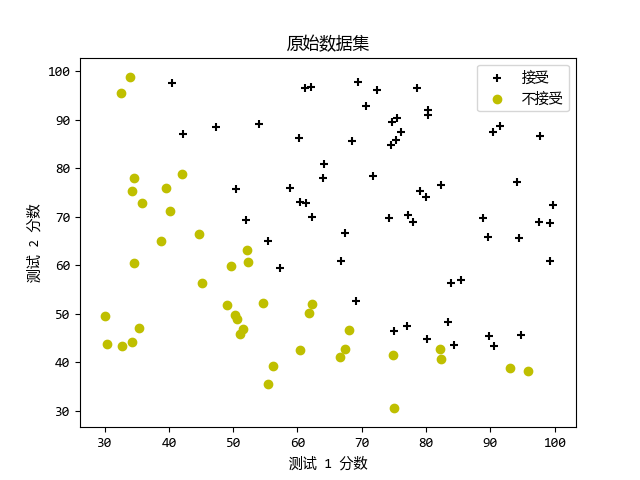
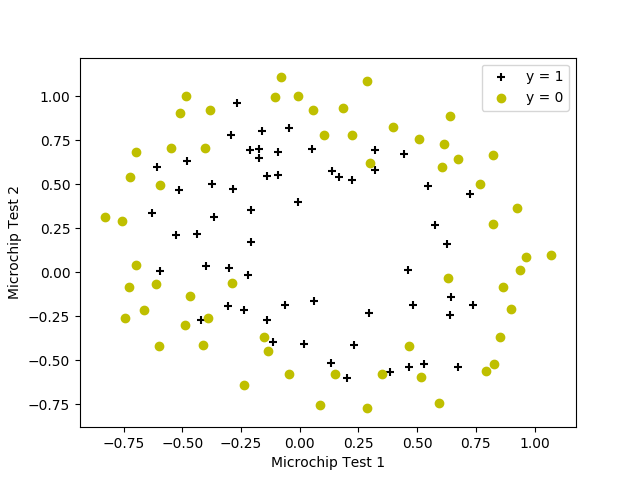
def plotData(X: np.ndarray, y: np.ndarray):
pos = [it for it in range(y.shape[0]) if y[it, 0] == 1]
neg = [it for it in range(y.shape[0]) if y[it, 0] == 0]
plt.figure()
plt.scatter(X[pos, 0], X[pos, 1], c='k', marker='+')
plt.scatter(X[neg, 0], X[neg, 1], c='y', marker='o')
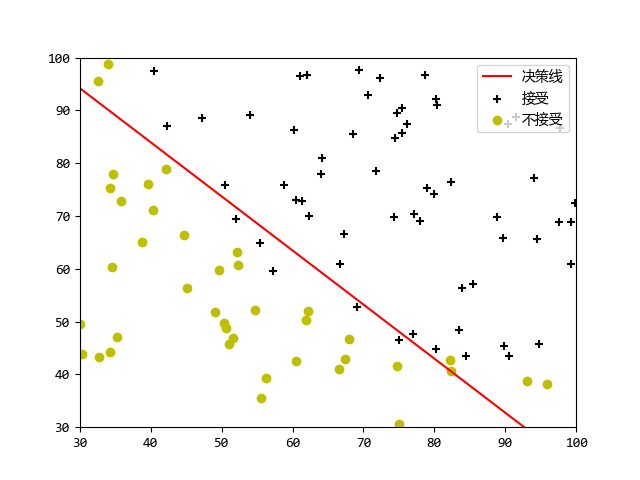
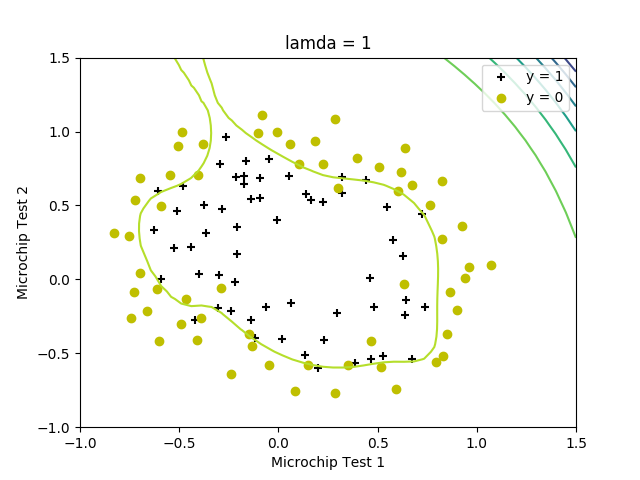
def plotDecisionBoundary(theta: np.ndarray, X: np.ndarray, y: np.ndarray):
plotData(X[:, 1:], y)
if X.shape[1] <= 3:
plot_x = np.array([min(X[:, 1])-2, max(X[:, 2])+2])
plot_y = np.zeros(plot_x.shape)
plot_y = (-1/theta[2, 0])*(theta[1, 0]*plot_x + theta[0, 0])
line = plt.plot(np.linspace(plot_x[0], plot_x[1]),
np.linspace(plot_y[0], plot_y[1]), color='r')
plt.legend(['决策线', '接受', '不接受'], loc='upper right')
plt.axis([30, 100, 30, 100])
else:
u = np.linspace(-1, 1.5, 50)
v = np.linspace(-1, 1.5, 50)
z = np.zeros((len(u), len(v)))
for i in range(len(u)):
for j in range(len(v)):
z[i, j] = mapFeature(np.mat(u[i]), np.mat(v[j]))@theta
z = z.T
plt.contour(u, v, z)
def costFunction(theta: np.ndarray, X: np.ndarray, y: np.ndarray):
m = y.shape[0]
J = 0
grad = np.zeros(theta.shape)
h = expit(X@theta)
J = np.sum(-y*np.log(h)-(1-y)*np.log(1-h)) / m
grad = X.T@(h-y)/m
return J, grad
def costFuc(theta: np.ndarray, X: np.ndarray, y: np.ndarray):
m = y.shape[0]
theta = theta.reshape(-1, 1)
h = expit(X@theta)
J = np.sum(-y*np.log(h)-(1-y)*np.log(1-h)) / m
return J
def gradFuc(theta: np.ndarray, X: np.ndarray, y: np.ndarray):
m = y.shape[0]
theta = theta.reshape(-1, 1)
grad = np.zeros(theta.shape)
h = expit(X@theta)
grad = X.T@(h-y)/m
return grad.flatten()
def predict(theta: np.array, X: np.array):
m = X.shape[0]
p = np.zeros((m, 1))
p = np.around(expit(X@theta))
return p
def mapFeature(X1: np.ndarray, X2: np.ndarray)->np.ndarray:
degree = 6
out = np.ones(
(X1.shape[0], sum([i for i in range(1, degree+2)])), dtype=float)
cnt = 0
for i in range(degree+1):
for j in range(i+1):
out[:, cnt] = np.power(X1, (i-j))*np.power(X2, j)
cnt += 1
return out
def costFunctionReg(theta: np.ndarray, X: np.ndarray, y: np.ndarray, lamda: np.ndarray):
m = y.shape[0]
J = 0
grad = np.zeros(theta.shape)
h = expit(X@theta)
J = np.sum(-y*np.log(h)-(1-y)*np.log(1-h)) / m \
+ lamda * np.sum(np.power(theta, 2)) / (2*m)
temptheta = np.zeros(theta.shape)
temptheta[1:, :] = theta[1:, :]
grad = (X.T@(h-y)+lamda * temptheta) / m
return J, grad
|