from models.yolonet import yoloconv import tensorflow as tf from tools.utils import helper import skimage import numpy as np from scipy.special import expit
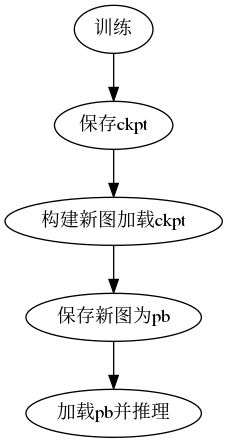
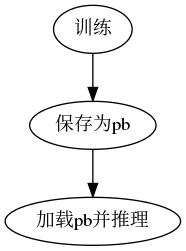
if __name__ == "__main__": tf.enable_eager_execution() fddb = helper('/home/zqh/Documents/faces/data/train.list', (224, 320), (7, 10)) gen = fddb.generator() tf.reset_default_graph() g = tf.Graph() g1 = tf.Graph() with g.as_default(): with tf.gfile.GFile('/home/zqh/Documents/faces/Training_save.pb', 'rb') as f: Training_save = tf.GraphDef() Training_save.ParseFromString(f.read()) tf.import_graph_def(Training_save, name='')
with g1.as_default(): with tf.gfile.GFile('/home/zqh/Documents/faces/Freeze_save.pb.pb', 'rb') as f: Freeze_save = tf.GraphDef() Freeze_save.ParseFromString(f.read()) tf.import_graph_def(Freeze_save, name='')
train_weights = [opt for opt in g.get_operations() if'read'in opt.name] train_weights = [g.get_tensor_by_name(opt.name+':0') for opt in train_weights]
freeze_weights = [opt for opt in g1.get_operations() if'read'in opt.name] freeze_weights = [g1.get_tensor_by_name(opt.name+':0') for opt in freeze_weights]
""" start compare weights """ with tf.Session(graph=g) as t_sess: t_var_dict = {} for var in train_weights: t_var_dict[var.name] = t_sess.run(var)
with tf.Session(graph=g1) as f_sess: f_var_dict = {} for var in freeze_weights: f_var_dict[var.name] = f_sess.run(var)
for name, value in t_var_dict.items(): # ! all weights are equal assert np.array_equal(t_var_dict[name], f_var_dict[name])
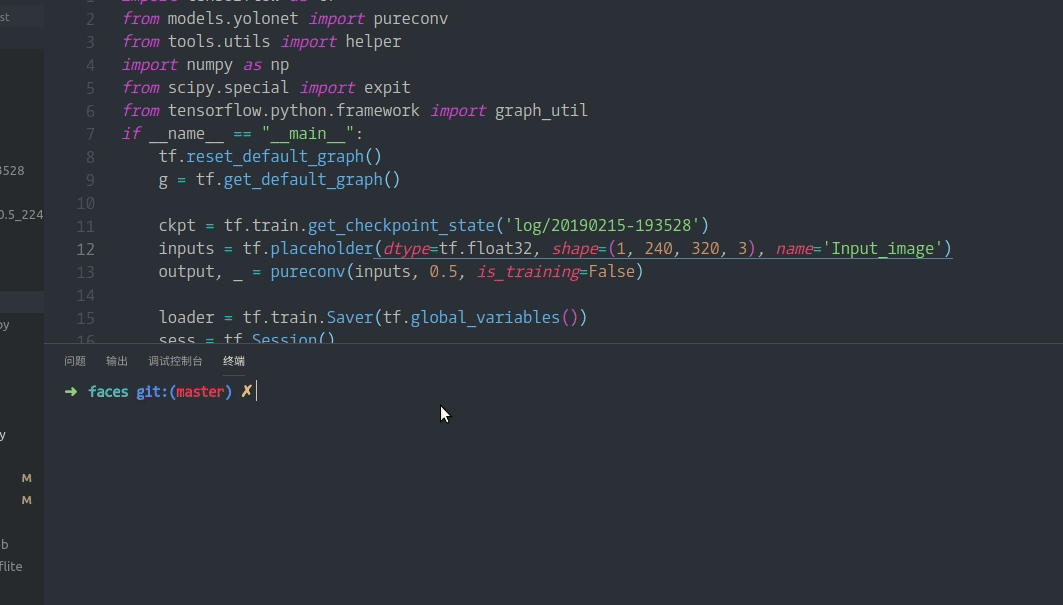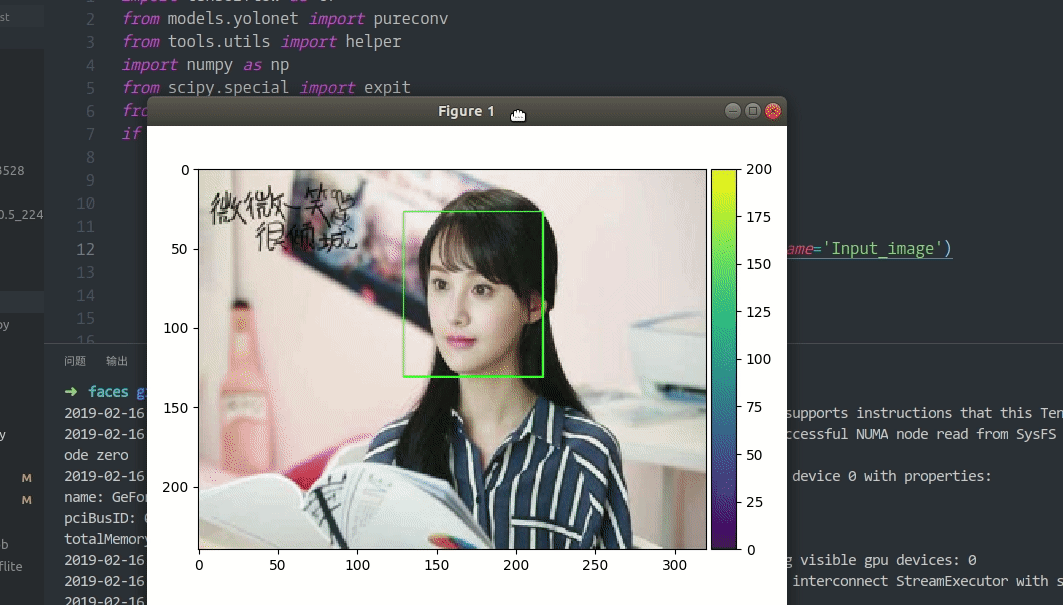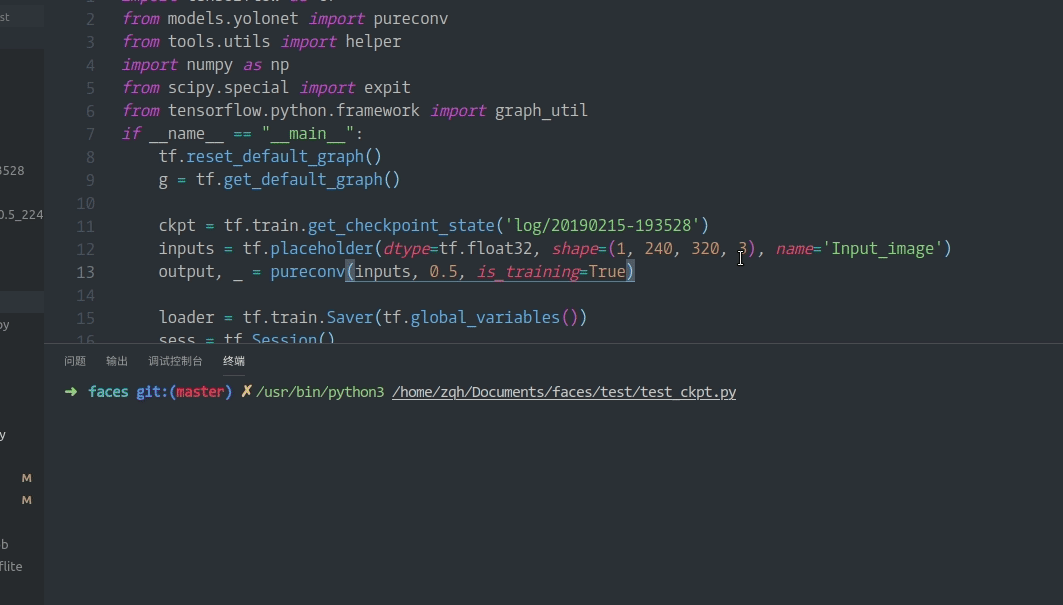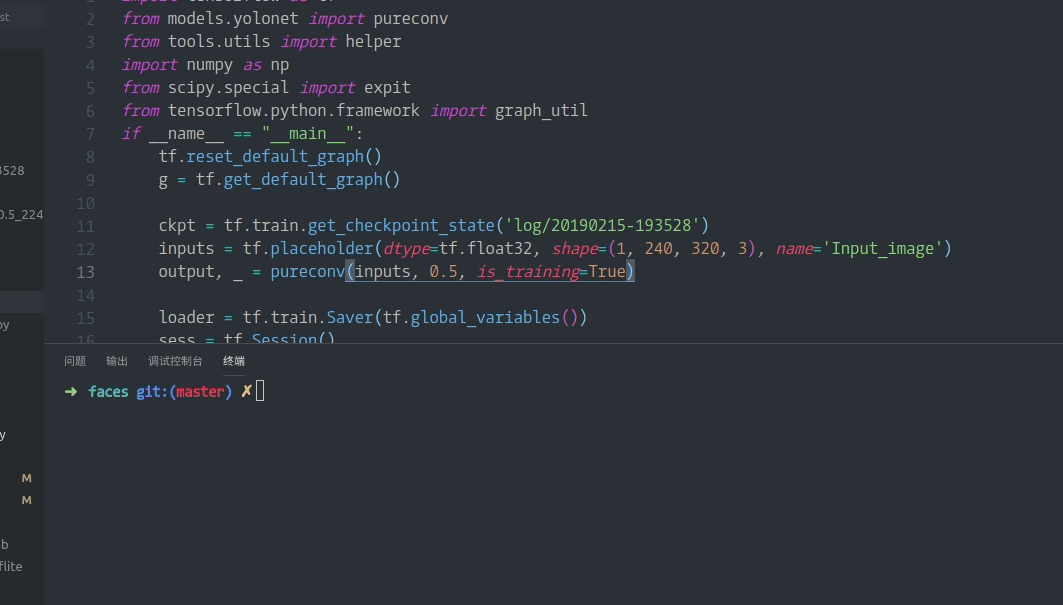
""" start test output """ img, label = next(gen) img = img[np.newaxis, :, :, :] with tf.Session(graph=g) as t_sess: t_output = t_sess.run(g.get_tensor_by_name('predict:0'), feed_dict={g.get_tensor_by_name('Input_image:0'): img})
with tf.Session(graph=g1) as f_sess: f_output = f_sess.run(g1.get_tensor_by_name('predict:0'), feed_dict={g1.get_tensor_by_name('Input_image:0'): img})
t_output = expit(t_output) f_output = expit(f_output) # ! array not equal Why ?? if np.array_equal(t_output, f_output): print('test success!') else: print('results not equal. Why ??')