解决目标检测任务测试集recall率低
我把Google官方的mobile-net模型拿来做迁移学习.在训练的过程中发现一个问题,在测试中对于目标的recall率十分低.经过了两天的尝试,大概找到了解决办法
问题描述
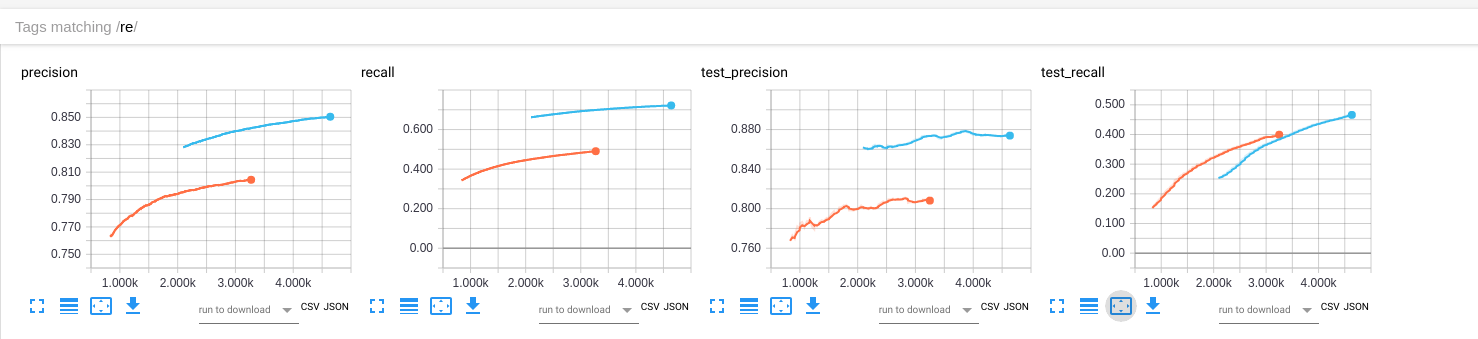
首先看precision和recall曲线,其中蓝色的是迁移学习模型训练过程,后面记为yolonet.橙色的是我自定义的模型训练过程,后面记为pureconv.
分析
可以发现我两个模型的测试与训练时的precision都较好,所以暂时不管.
接着看recall,在训练期间,yolonet明显好于pureconv.但是在测试期间情况却相反了.
Batch norm
这个原因我很快否决了.因为我上一次就已经解决.
过拟合
有的人说这是典型的过拟合,但是我可以确认这完全不是过拟合,因为我才训练一千的
step是不应该出现过拟合的情况.当然,我这样说也缺乏证据.必须要绘制出bias-variance曲线才可以证明.(目标检测任务中的bias-variance曲线我还需要去了解如何计算)神经元被抑制
这是我的猜想.不过我确实发现了问题所在.
问题解决
我查看了模型的代码发现,模型定义的时候增加了l2_regularizer,它应该是罪魁祸首:
batch_norm_params = {
'center': True,
'scale': True,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'updates_collections': batch_norm_updates_collections,
}
if is_training is not None:
batch_norm_params['is_training'] = is_training
# Set weight_decay for weights in Conv and DepthSepConv layers.
weights_init = tf.truncated_normal_initializer(stddev=stddev)
regularizer = tf.contrib.layers.l2_regularizer(weight_decay)
if regularize_depthwise:
depthwise_regularizer = regularizer
else:
depthwise_regularizer = None
with slim.arg_scope([slim.conv2d, slim.separable_conv2d],
weights_initializer=weights_init,
activation_fn=tf.nn.relu6, normalizer_fn=normalizer_fn):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.conv2d], weights_regularizer=regularizer):
with slim.arg_scope([slim.separable_conv2d],
weights_regularizer=depthwise_regularizer) as sc:
return sc
然后我删去了正则化部分.
同时把Batch norm的decay参数从0.9997设置到了0.999,这样加快的归一化的学习速度.
原因: \[ variable = variable - (1 - decay) * (variable - value) \]
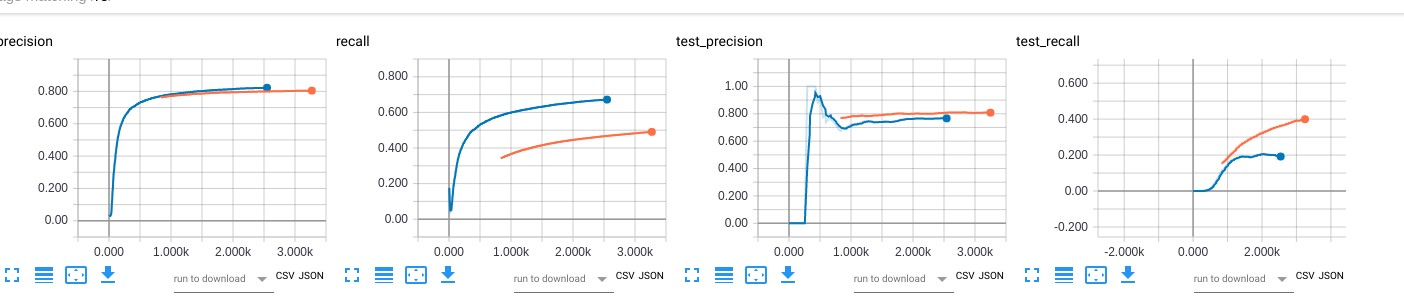
效果
可以看到,现在yoloconv的效果都高于pureconv.