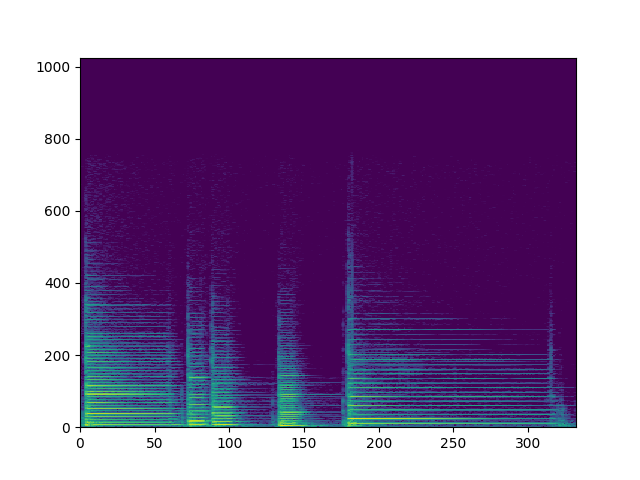
# Read wav file # "OSR_us_000_0010_8k.wav" is downloaded from http://www.voiptroubleshooter.com/open_speech/american.html sample_rate, signal = scipy.io.wavfile.read("../sms-tools-master/sounds/piano.wav") # Get speech data in the first 2 seconds # 只取2s钟时间 signal = signal[0:int(2. * sample_rate)]
# Calculate the short time fourier transform pow_spec = calc_stft(signal, sample_rate)
import numpy as np import matplotlib.pyplot as plt import os import sys from scipy.signal import get_window from scipy.io import wavfile
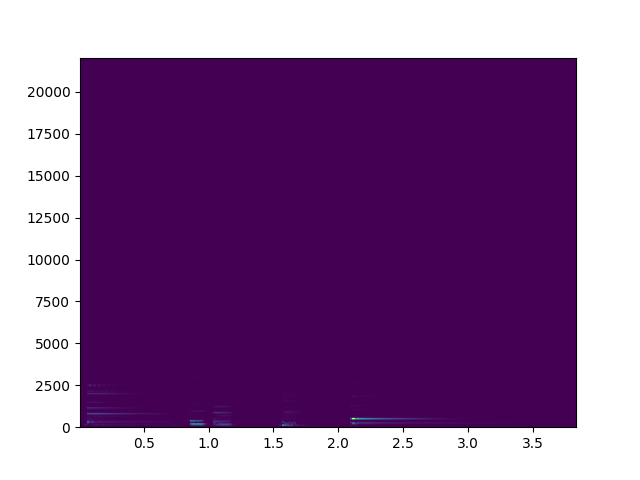
inputfile = "../sms-tools-master/sounds/piano.wav" window = 'hamming' M = 801 N = 1024 H = 400 fs, x = wavfile.read(inputfile) w = get_window(window, M)
import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import librosa from scipy.io import wavfile from scipy import fft
y, sr = librosa.load("../sms-tools-master/sounds/piano.wav", sr=None) # d = librosa.amplitude_to_db(np.abs(librosa.stft(x, n_fft=512, hop_length=512))) # plt.pcolormesh(d.T) # plt.show()
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt from scipy.signal import get_window from scipy.io import wavfile from scipy.signal import spectrogram, windows import numpy as np