人脸识别方法总结
要搞个人脸识别的应用,花了半天时间浏览一下,准备基于open face的模型来做移植。下面是对开源库face-recognition的使用指南进行一个翻译,看了一下基本知道了大致流程。不过我记得上次写过L softmx -> A
softmx -> AM
softmax的这些loss都是用在人脸识别里面的,但是如果基于softmax loss的话,每加一个人脸不都是要重新训练一波吗?不知道是不是这个情况,目前还没看到别的方式。
Deep face recognition with Keras, Dlib and OpenCV
面部识别识别面部图像或视频帧上的人。简而言之,人脸识别系统从输入人脸图像中提取特征,并将其与数据库中标记人脸的特征进行比较。比较基于特征相似性度量,并且最相似的数据库条目的标签用于标记输入图像。如果相似度值低于某个阈值,则输入图像标记为unknown。比较两个面部图像以确定它们是否显示同一个人被称为面部验证。
该笔记本使用深度卷积神经网络(CNN)从输入图像中提取特征。它遵循1中描述的方法,其修改受OpenFace项目的启发。 Keras用于实现CNN,Dlib和OpenCV用于对齐面部在输入图像上。在LFW数据集的一小部分上评估面部识别性能,您可以将其替换为您自己的自定义数据集,例如:如果你想进一步试验这款笔记本,请附上你的家人和朋友的照片。在概述了CNN架构以及如何训练模型之后,将演示如何:
- 在输入图像上检测,变换和裁剪面部。这可确保面部在进入CNN之前对齐。该预处理步骤对于神经网络的性能非常重要。
- 使用CNN从对齐的输入图像中提取面部的128维表示或嵌入。在嵌入空间中,欧几里德距离直接对应于面部相似性的度量。
- 将输入嵌入向量与数据库中标记的嵌入向量进行比较。这里,支持向量机(SVM)和KNN分类器,在标记的嵌入向量上训练,起到数据库的作用。在此上下文中的面部识别意味着使用这些分类器来预测标签,即新输入的身份。
Environment setup 环境设置
For running this notebook, create and activate a new virtual
environment and install the packages listed in requirements.txt with
pip install -r requirements.txt. Furthermore, you'll need a
local copy of Dlib's face landmarks data file for running face
alignment:
CNN architecture and training
这里使用的CNN架构是初始架构2的变体。更确切地说,它是1中描述的NN4体系结构的变体,并标识为nn4.small2。这个笔记本使用该模型的Keras实现,其定义取自Keras-OpenFace项目。这里的体系结构细节并不太重要,只知道有一个完全连接的层,其中有128个隐藏单元,后面是卷积基础顶部的L2规范化层。这两个顶层被称为嵌入层,从中可以获得128维嵌入向量。完整模型在[model.py](model.py)中定义,图形概述在[model.png](model.png)中给出。可以使用create_model()创建nn4.small2模型的Keras版本。
from model import create_model |
W0801 21:29:26.376736 140043235366720 deprecation.py:506] From /home/zqh/miniconda3/lib/python3.7/site-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor模型训练旨在学习嵌入\(f(x)\)图像\(x\),使得相同身份的所有面部之间的平方L2距离较小,并且来自不同身份的一对面部之间的距离较大。当嵌入空间中的锚图像\(x^a_i\)和正图像\(x^p_i\)(相同身份)之间的距离小于两者之间的距离时,可以实现三元组损失 \(L\)。锚图像和负图像\(x^n_i\)(不同的身份)至少有一个边缘\(\alpha\)。
\[ \begin{aligned} L = \sum^{m}_{i=1} \large[ \small {\mid \mid f(x_{i}^{a}) - f(x_{i}^{p})) \mid \mid_2^2} - {\mid \mid f(x_{i}^{a}) - f(x_{i}^{n})) \mid \mid_2^2} + \alpha \large ] \small_+ \end{aligned} \]
\([z]_+\)表示\(\max(z,0)\)和\(m\)是训练集中三元组的数量。
Keras中的三重态损失最好用自定义层实现,因为损失函数不遵循通常的“损失(输入,目标)”模式。该层调用self.add_loss来安装三元组丢失:
from tensorflow.python.keras import backend as K |
在训练期间,选择正对\((x^a_i,x^p_i)\)和负对\((x^a_i,x^n_i)\)难以区分的三元组是很重要的,即它们在嵌入空间中的距离差异应该是低于间距\(\alpha\),否则,网络无法学习有用的嵌入。因此,每次训练迭代应该基于在前一次迭代中学习的嵌入来选择一批新的三元组。假设从triplet_generator()调用返回的生成器可以在这些约束下生成三元组,可以通过以下方式训练网络:
from data import triplet_generator |
W0801 21:29:38.732154 140043235366720 training_utils.py:1101] Output triplet_loss_layer missing from loss dictionary. We assume this was done on purpose. The fit and evaluate APIs will not be expecting any data to be passed to triplet_loss_layer.
W0801 21:29:38.856654 140043235366720 deprecation.py:323] From /home/zqh/miniconda3/lib/python3.7/site-packages/tensorflow/python/ops/math_grad.py:1250: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
Epoch 1/10
100/100 [==============================] - 19s 191ms/step - loss: 0.8117
Epoch 2/10
100/100 [==============================] - 5s 46ms/step - loss: 0.7971
Epoch 3/10
100/100 [==============================] - 5s 46ms/step - loss: 0.8035
Epoch 4/10
100/100 [==============================] - 5s 46ms/step - loss: 0.8018
Epoch 5/10
100/100 [==============================] - 5s 46ms/step - loss: 0.8049
Epoch 6/10
100/100 [==============================] - 5s 46ms/step - loss: 0.8009
Epoch 7/10
100/100 [==============================] - 5s 47ms/step - loss: 0.8003
Epoch 8/10
100/100 [==============================] - 5s 48ms/step - loss: 0.7995
Epoch 9/10
100/100 [==============================] - 5s 46ms/step - loss: 0.8004
Epoch 10/10
100/100 [==============================] - 5s 46ms/step - loss: 0.7998
<tensorflow.python.keras.callbacks.History at 0x7f5cda4385c0>上面的代码片段应该只演示如何设置模型训练。但是,我们不是从头开始实际训练模型,而是使用预先训练的模型,因为从头开始的训练非常昂贵,并且需要庞大的数据集来实现良好的泛化性能。例如,[1](https://arxiv.org/abs/1503.03832)使用包含大约8M身份的200M图像的数据集。
OpenFace项目提供了预训练模型,这些模型使用公共人脸识别数据集FaceScrub进行训练,和CASIA-WebFace。
Keras-OpenFace项目将预先训练的nn4.small2.v1模型的权重转换为CSV文件,然后进行转换这里x为一个二进制格式,可由Keras用load_weights加载:
nn4_small2_pretrained = create_model() |
Custom dataset 自定义数据集
为了演示自定义数据集上的人脸识别,使用了LFW数据集的一小部分。它由10个身份的100个面部图像组成。每个图像的元数据(文件和身份名称)被加载到内存中以供以后处理。
import numpy as np |
Face alignment 面部对齐
nn4.small2.v1模型使用对齐的面部图像进行训练,因此,自定义数据集中的面部图像也必须对齐。在这里,我们使用Dlib进行人脸检测,使用OpenCV进行图像变换和裁剪,以生成对齐的96x96 RGB人脸图像。通过使用OpenFace项目中的AlignDlib实用程序,这很简单:
import cv2 |

如OpenFace 预训练模型中所述部分,模型nn4.small2.v1需要地标索引OUTER_EYES_AND_NOSE。让我们将面部检测,转换和裁剪实现为align_image函数,以便以后重用。
def align_image(img): |
Embedding vectors 嵌入向量
现在可以通过将对齐和缩放的图像馈送到预训练的网络中来计算嵌入向量。
embedded = np.zeros((metadata.shape[0], 128)) |
Let's verify on a single triplet example that the squared L2 distance between its anchor-positive pair is smaller than the distance between its anchor-negative pair.
让我们在单个三元组示例上验证其锚定正对之间的平方L2距离小于其锚定负对之间的距离。
def distance(emb1, emb2): |


正如预期的那样,Jacques Chirac的两幅图像之间的距离小于Jacques Chirac图像与GerhardSchröder图像之间的距离(0.30 <1.12)。但是我们仍然不知道距离阈值\(\tau\)是在相同身份和不同身份之间作出决定的最佳边界。
Distance threshold 距离阈值
要查找$ $的最佳值,必须在一系列距离阈值上评估面部验证性能。在给定阈值处,所有可能的嵌入向量对被分类为相同的身份或不同的身份并且与基础事实进行比较。因为我们正在处理偏斜的类(比正对更多的负对),我们使用F1得分作为评估指标而不是准确度
from sklearn.metrics import f1_score, accuracy_score |
/home/zqh/miniconda3/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 216, got 192
return f(*args, **kwds)
/home/zqh/miniconda3/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
return f(*args, **kwds)
/home/zqh/miniconda3/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject
return f(*args, **kwds)
/home/zqh/miniconda3/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 216, got 192
return f(*args, **kwds)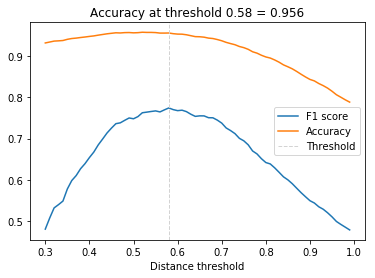
\(\tau\) = 0.56的面部验证准确率为95.7%。对于总是预测不同身份(有980个pos。对和8821个neg。对)的分类器的基线为89%,这也不错,但由于nn4.small2.v1是一个相对较小的模型,它仍然小于最先进的模型(> 99%)。
以下两个直方图显示了正负对的距离分布和决策边界的位置。这些分布明显分开,这解释了网络的辨别性能。人们也可以发现正对中的一些强异常值,但这里不再进一步分析。
dist_pos = distances[identical == 1] |

Face recognition 人脸识别
给定距离阈值$ \(的估计,人脸识别现在就像计算输入嵌入向量与数据库中所有嵌入向量之间的距离一样简单。如果输入小于\) $或标签unknown,则为输入分配具有最小距离的数据库条目的标签(即标识)。此过程还可以扩展到大型数据库,因为它可以轻松并行化。它还支持一次性学习,因为仅添加新标识的单个条目可能足以识别该标识的新示例。
更稳健的方法是使用数据库中的前$ k $评分条目标记输入,该条目基本上是KNN分类,具有欧几里德距离度量。或者,线性支持向量机可以用数据库条目训练并用于分类,即识别新输入。为了训练这些分类器,我们使用50%的数据集,用于评估其他50%。
from sklearn.preprocessing import LabelEncoder |
KNN accuracy = 0.96, SVM accuracy = 0.98KNN分类器在测试集上实现了96%的准确度,SVM分类器为98%。让我们使用SVM分类器来说明单个示例中的人脸识别。
import warnings |

似乎合理:-)实际上应该检查分类结果是否(预测身份的数据库条目的一个子集)的距离小于\(\tau\),否则应该分配一个未知标签。此处跳过此步骤,但可以轻松添加。
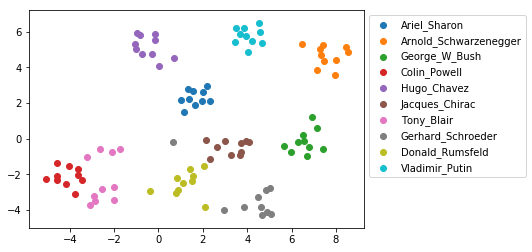
Dataset visualization 数据集可视化
为了将数据集嵌入到2D空间中以显示身份聚类,将t-distributed Stochastic Neighbor Embedding(t-SNE)应用于128维嵌入向量。除了一些异常值,身份集群很好地分开。
from sklearn.manifold import TSNE |