Tensorflow中的错误记录
以后这篇文章就来记录tensorflow中遇到的问题与解决方式。
1. 自定义loss中的reshape问题
我想在loss函数中对tensor进行reshape,在model.compile的时候,keras会生成两个虚placeholder来进行尺寸检查,比如我的yolo中的y_true会生成为(?, ?, ?, ?, ?),y_pred会按照tf.dataset来生成(?, 7, 10, 5, 16)。
这个时候我对标签reshape给的参数为tf.TensorShape(None, 7, 10, 5, 8, 2),但是报错如下:
ValueError: Tried to convert 'shape' to a tensor and failed. Error: Cannot convert a partially known TensorShape to a Tensor: (?, 7, 10, 5, 5, 2)解决方式:
咋一看这个出错好像很蠢,但其实是因为在尺寸检查的时候不接受未知的尺寸None,所以把上面修改为:tf.TensorShape(batch_size, 7, 10, 5, 8, 2)即可。
2. Map_fn或者While_Loop速度很慢
这个问题的确很蛋疼,我看了github的issue,这两个函数都不能有效的进行GPU加速,但是我又需要对一个batch中的每个样本对进行单独处理,这就很难受。
解决方式:
还好tensorflow的构建可以是静态图的方式,像我这样知道batch size的情况下,就可以使用在构建graph的时候循环构建一波。如:
masks = []
for bc in range(helper.batch_size):
vaild_xy = tf.boolean_mask(t_xy_A[bc], obj_mask[bc])
vaild_wh = tf.boolean_mask(t_wh_A[bc], obj_mask[bc])
iou_score = tf_iou(pred_xy[bc], pred_wh[bc], vaild_xy, vaild_wh)
best_iou = tf.reduce_max(iou_score, axis=-1, keepdims=True)
masks.append(tf.cast(best_iou < iou_thresh, tf.float32))
tf.parallel_stack(masks)
3. 使用tf.keras构建模型时Tensorboard无法显示graph
之前我写yolo的时候,使用Tensorboard去查看图形时,一直显示如下
Graph visualization failed
Error: The graph is empty. This can happen when TensorFlow could not trace any graph. Please refer to https://github.com/tensorflow/tensorboard/issues/1961 for more information.然后我看了issue,全是因为tf2的eager的原因,我这里又没有用这个模式,怎么会出这个问题呢。
解决方式:
找了半天解决方式,就是没找到,我本来想按照以前的方式做,忽然发现就可以了,在callback之后加一句话即可,如下:
cbs.append(TensorBoard(str(log_dir), update_freq='batch', profile_batch=3)) |
4. tf.keras中Model复用
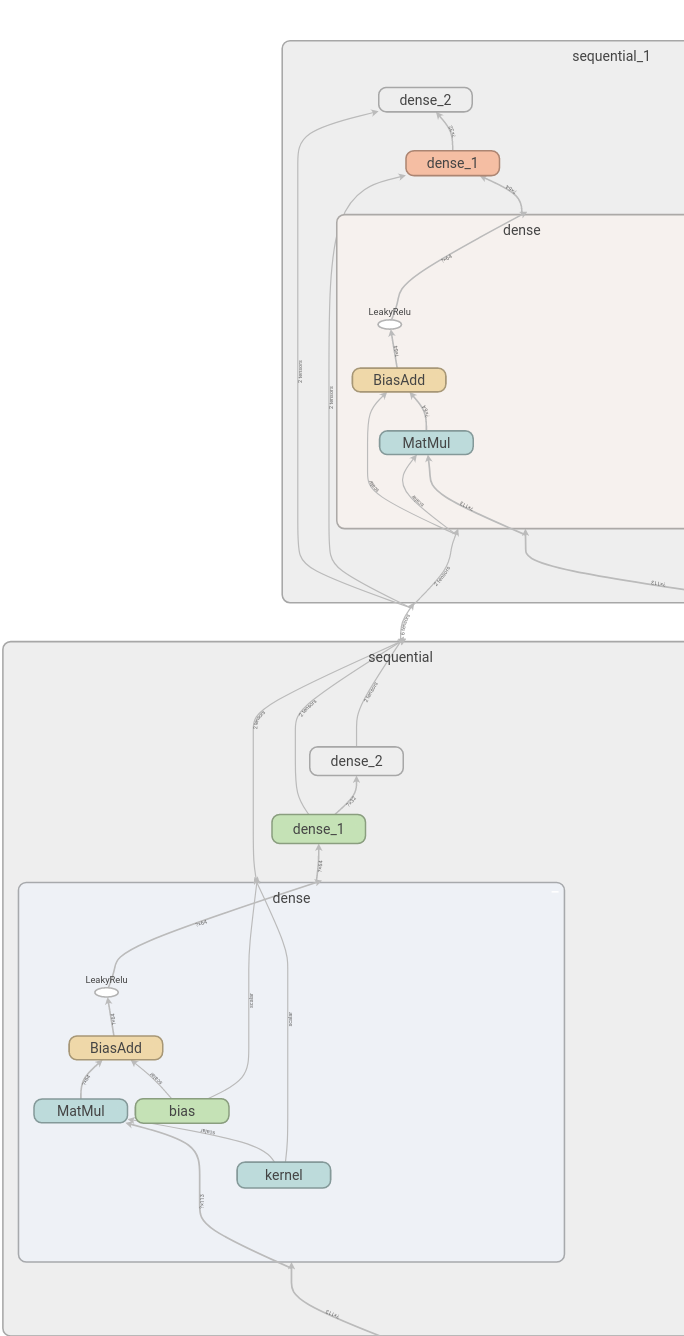
这个其实不算问题,只不过我不太清楚,就做了个测试来验证一下。就是比如我们用Sequential构建了一个body部分,然后用这个body产生多个输出,我一开始不知道他这样使用是否是公用参数了,然后我就写了个函数测试了下:
input_sim = k.Input((113)) |
结果:
这样的复用方式是共享参数的,可以看到,两个sequential,一个含有kernel,另一个没有,或者说他们公用一个kernel。
5. Error while reading resource variable xxx from Container: localhost. This could mean that the variable was uninitialized.
我想在tf.keras里面使用苏神的Lookahead,他的代码是用于纯keras的,但是我现在用tf.keras,虽然表层使用看起来差不多,但是核心代码我发现还是很多都不一样。我的问题出现在这里:
fast_params = model._collected_trainable_weights |
使用K.variable转换参数的时候出错了,说我的变量没有被初始化。
tensorflow.python.framework.errors_impl.FailedPreconditionError: Error while reading resource variable batch_normalization/gamma from Container: localhost. This could mean that the variable was uninitialized. Not found: Resource localhost/batch_normalization/gamma/N10tensorflow3VarE does not exist.
[[{{node training/RAdam/Variable_274/Initializer/ReadVariableOp}}]]
解决方案:
google了一下也没看到有人有相同的问题,我抱着试试看的心态写了如下代码:
sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()]) |
在model.compile之前全局初始化,然后就完事了?然后就可以用上最新的优化算法RAdam和Lookahead咯。
6. tf.data对于多输入多输出模型时的操作
我现在的模型是3输入,2输出的,tf.data输出的应该为( (a,b,c)
, (label_a,label_b) ),然后我原本代码如下:
return [a_img, p_img, n_img], [1., 1.] |
然后dataset对象就是这样: <DatasetV1Adapter shapes: ((32, 3, 96, 96, 3), (32, 2)), types: (tf.float32, tf.float32)>
解决方案:
用元组即可,不然默认是一个张量对象,会把我们的结构破坏掉. return (a_img, p_img, n_img), (1., 1.)
dataset对象就是这样: <DatasetV1Adapter shapes: (((32, 96, 96, 3), (32, 96, 96, 3), (32, 96, 96, 3)), ((32,), (32,))), types: ((tf.float32, tf.float32, tf.float32), (tf.float32, tf.float32))>