半监督学习:FixMatch
第十个算法FixMatch: Simplifying Semi-Supervised Learning withConsistency and Confidence,这依旧是谷歌研究组的作者提出的,是对MixMatch的改进。
算法理论
FixMatch简而言之是一致性正则与伪标签的简单组合,他的主要创新点在于如何结合,以及在执行一致性正则是单独使用弱增强与强增强。这里的符号还是和之前的文章一样,新添加强增强符号为\(\mathcal{A}(\cdot)\)和弱增强\(\alpha(\cdot)\)。他的损失函数只由两个交叉熵组成:有监督的交叉熵\(\ell_{s}\)和无监督交叉熵\(\ell_{u}\)。对于有标签数据只使用弱增强并计算交叉熵:
\[ \begin{align} \ell_{s}=\frac{1}{B} \sum_{b=1}^{B} \mathrm{H}\left(p_{b}, p_{\mathrm{m}}\left(y | \alpha\left(x_{b}\right)\right)\right) \end{align} \]
对于无标签数据,首先计算人工标签再用它来计算交叉熵。为了获得人工标签,首先计算给定的弱增强无标签图像的分布:\(q_b=\_m(y|\alpha(u_b))\)。然后使用\(\hat{q}_{b}=\arg \max \left(q_{b}\right)\)作为伪标签,接着使模型学习强增强的无标签样本的分类类别: \[ \begin{align} \ell_{u}=\frac{1}{\mu B} \sum_{b=1}^{\mu B} \mathbb{1}\left(\max \left(q_{b}\right) \geq \tau\right) \mathrm{H}\left(\hat{q}_{b}, p_{\mathrm{m}}\left(y | \mathcal{A}\left(u_{b}\right)\right)\right) \end{align} \]
其中\(\tau\)为保留阈值,如果伪标签的置信度不够高,那么需要丢弃这部分损失。综合损失为如下:\(\ell_s+\lambda_u\ell_u\),其中\(\lambda_u\)为权重参数。
FixMatch中的增强
其中弱增强为50%随机水平翻转,12.5%随机上下翻转,并添加一部分水平平移。对于强增强,使用了RandAugment和CTAugment。
对于RandAugment他使用一个全局的幅度来控制增强,幅度是通过验证集来优化的。不过论文中发现每个step直接从预定义范围中随机采样幅度即可获得良好的效果,方法类似与UDA。
对于CTAugment,在ReMixMatch讲过了。
其他重要因素
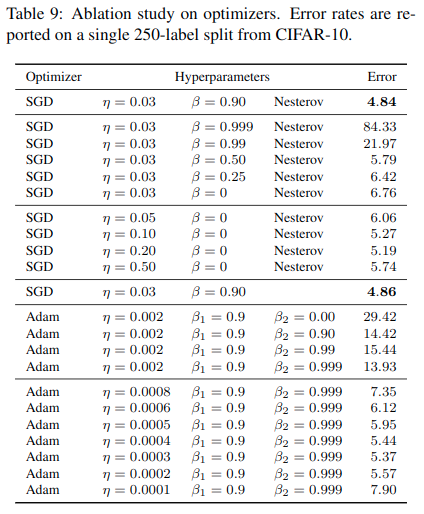
发现对于优化器,使用Adam反而效果不好。对于学习率衰减,使用余弦衰减比较好。
相关工作总结
| 算法 | 人工标签增强 | 预测增强 | 人工标签后处理 | 备注 |
|---|---|---|---|---|
| Π-Model | 弱 | 弱 | 无 | |
| Temporal Ensembling | 弱 | 弱 | 无 | 使用较早训练的模型 |
| Mean Teacher | 弱 | 弱 | 无 | 使用参数指数移动平滑 |
| Virtual Adversarial Training | 无 | 对抗 | 无 | |
| UDA | 无 | 强 | 锐化 | 忽略低置信度的人工标签 |
| MixMatch | 弱 | 弱 | 锐化 | 平均多个人工标签 |
| ReMixMatch | 弱 | 强 | 锐化 | 汇总多个预测的损失 |
| FixMatch | 弱 | 强 | 伪标签 |
实际上经过MixMatch,ReMixMatch中大量的消融测试,作者应该已经找到了其中最重要的几个因素,所以这篇论文的理论部分比较少,因为之前的论文都已经介绍过了。实际上我认为主要加强点还是在于如何更好的使用一致性正则化,弱增强与弱增强间的所能学习到的一致性还不够,需要在弱增强与强增强间学习。同时对于人工标签的处理方式相当于选择如何进行熵最小化,也是次重要的。
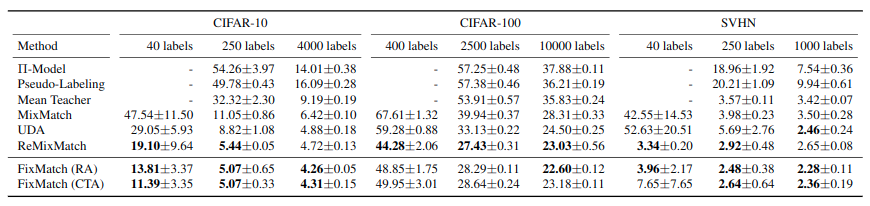
实验结果
消融测试
这里的消融测试主要就是在优化器上的了。
代码
实际上他这里的训练流程代码不算复杂,但是他的数据增强部分我暂时也没有搞懂,需要花点时间仔细看看。
AUGMENT_POOL_CLASS = AugmentPoolCTACutOut |
测试结果
使用默认参数以及cifar10中250张标注样本训练128个epoch,得到测试集准确率如下,比UDA高一些:
"last01": 84.94000244140625, |
相比于MixMatch是又快又好。