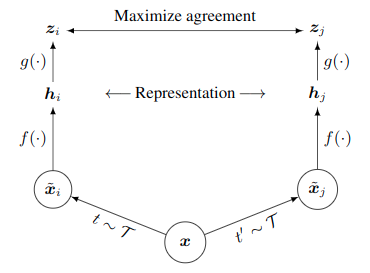
SimCLR实际上是Geoffrey Hinton和谷歌合作的论文A Simple Framework for Contrastive Learning of Visual Representations,严格来说他是一个自监督算法,不过我这里也把他归入半监督中了,他实际上是先无监督预训练然后进行监督微调的。
with tf.variable_scope('base_model'): if FLAGS.train_mode == 'finetune'and FLAGS.fine_tune_after_block >= 4: # Finetune just supervised (linear) head will not update BN stats. model_train_mode = False else: # Pretrain or finetuen anything else will update BN stats. model_train_mode = is_training hiddens = model(features, is_training=model_train_mode)
# Add head and loss. if FLAGS.train_mode == 'pretrain': tpu_context = params['context'] if'context'in params elseNone hiddens_proj = model_util.projection_head(hiddens, is_training)
图像输入到basemodel得到隐含层输出,再通过投影头得到隐含层投影hiddens_proj。
对比损失计算
defadd_contrastive_loss(hidden, hidden_norm=True, temperature=1.0, tpu_context=None, weights=1.0): """Compute loss for model. Args: hidden: hidden vector (`Tensor`) of shape (bsz, dim). hidden_norm: whether or not to use normalization on the hidden vector. temperature: a `floating` number for temperature scaling. tpu_context: context information for tpu. weights: a weighting number or vector. Returns: A loss scalar. The logits for contrastive prediction task. The labels for contrastive prediction task. """ # Get (normalized) hidden1 and hidden2. if hidden_norm: hidden = tf.math.l2_normalize(hidden, -1) hidden1, hidden2 = tf.split(hidden, 2, 0) batch_size = tf.shape(hidden1)[0]
# Gather hidden1/hidden2 across replicas and create local labels. if tpu_context isnotNone: hidden1_large = tpu_cross_replica_concat(hidden1, tpu_context) hidden2_large = tpu_cross_replica_concat(hidden2, tpu_context) enlarged_batch_size = tf.shape(hidden1_large)[0] # TODO(iamtingchen): more elegant way to convert u32 to s32 for replica_id. replica_id = tf.cast(tf.cast(xla.replica_id(), tf.uint32), tf.int32) labels_idx = tf.range(batch_size) + replica_id * batch_size labels = tf.one_hot(labels_idx, enlarged_batch_size * 2) masks = tf.one_hot(labels_idx, enlarged_batch_size) else: hidden1_large = hidden1 hidden2_large = hidden2 labels = tf.one_hot(tf.range(batch_size), batch_size * 2) masks = tf.one_hot(tf.range(batch_size), batch_size) logits_aa = tf.matmul(hidden1, hidden1_large, transpose_b=True) / temperature logits_aa = logits_aa - masks * LARGE_NUM logits_bb = tf.matmul(hidden2, hidden2_large, transpose_b=True) / temperature logits_bb = logits_bb - masks * LARGE_NUM logits_ab = tf.matmul(hidden1, hidden2_large, transpose_b=True) / temperature logits_ba = tf.matmul(hidden2, hidden1_large, transpose_b=True) / temperature