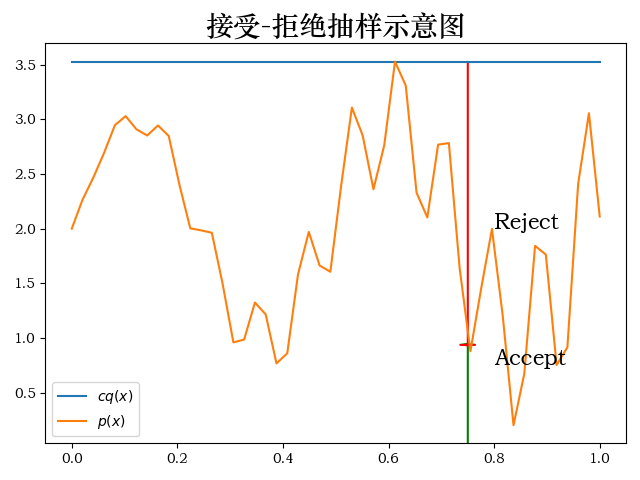
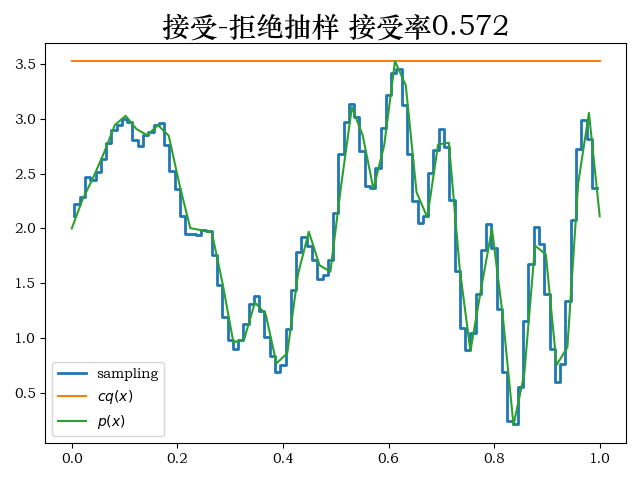
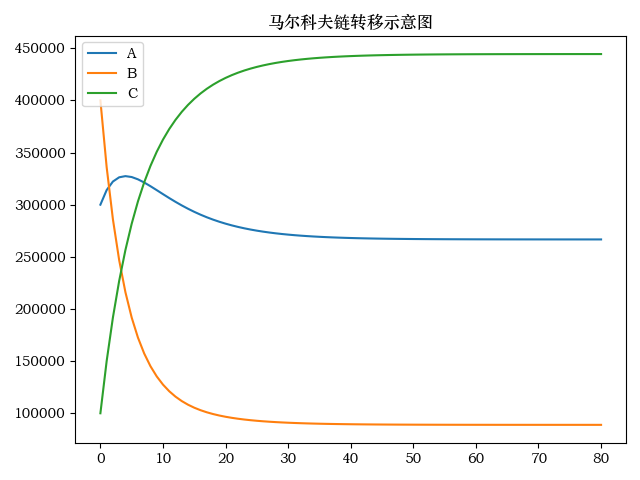
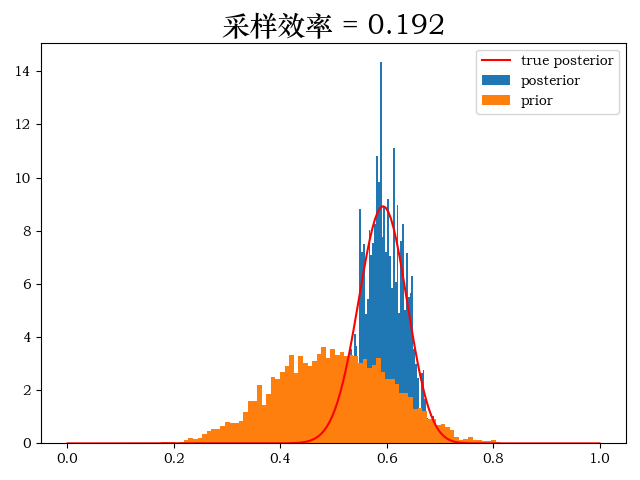
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm, binom, beta, uniform, bernoulli, gaussian_kde, multivariate_normal
from toolz import partial
plt.rcParams['font.sans-serif'] = ['STZhongsong']
plt.rcParams['axes.unicode_minus'] = False
def binom2(p1, p2, k1, k2, N1, N2):
""" 二维伯努利分布 """
return binom.pmf(k1, N1, p1) * binom.pmf(k2, N2, p2)
def make_thetas(xmin, xmax, n):
xs = np.linspace(xmin, xmax, n)
widths = (xs[1:] - xs[:-1]) / 2.0
thetas = xs[:-1] + widths
return thetas
def make_plots(X, Y, prior, likelihood, posterior, projection=None):
fig, ax = plt.subplots(1, 3, subplot_kw=dict(
projection=projection), figsize=(12, 3))
if projection == '3d':
ax[0].plot_surface(X, Y, prior, alpha=0.3, cmap=plt.cm.jet)
ax[1].plot_surface(X, Y, likelihood, alpha=0.3, cmap=plt.cm.jet)
ax[2].plot_surface(X, Y, posterior, alpha=0.3, cmap=plt.cm.jet)
for ax_ in ax:
ax_._axis3don = False
else:
ax[0].contour(X, Y, prior, cmap=plt.cm.jet)
ax[1].contour(X, Y, likelihood, cmap=plt.cm.jet)
ax[2].contour(X, Y, posterior, cmap=plt.cm.jet)
ax[0].set_title('Prior')
ax[1].set_title('Likelihood')
ax[2].set_title('Posteior')
thetas1 = make_thetas(0, 1, 101)
thetas2 = make_thetas(0, 1, 101)
X, Y = np.meshgrid(thetas1, thetas2)
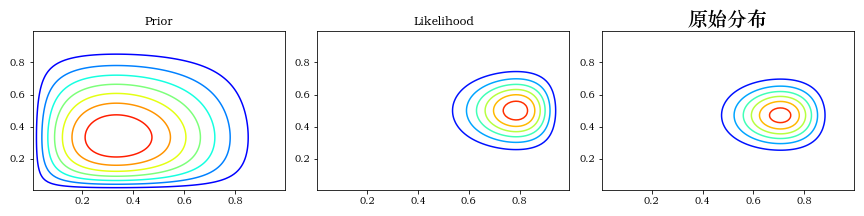
""" 先验分布参数 """
a = 2
b = 3
""" 似然分布参数 """
k1 = 11
N1 = 14
k2 = 7
N2 = 14
prior = beta(a, b).pdf(X) * beta(a, b).pdf(Y)
likelihood = binom2(X, Y, k1, k2, N1, N2)
posterior = beta(a + k1, b + N1 - k1).pdf(X) * beta(a + k2, b + N2 - k2).pdf(Y)
make_plots(X, Y, prior, likelihood, posterior)
plt.title(f"原始分布", fontsize=20)
plt.tight_layout(True)
plt.show()
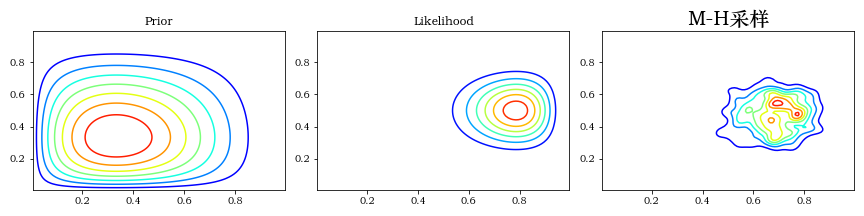
""" M-H采样 """
def prior(theta1, theta2): return beta(a, b).pdf(theta1) * beta(a, b).pdf(theta2)
lik = partial(binom2, k1=k1, k2=k2, N1=N1, N2=N2)
def target(theta1, theta2): return prior(theta1, theta2) * lik(theta1, theta2)
sigma = np.diag([0.2, 0.2])
def proposal(theta): return multivariate_normal(theta, sigma).rvs()
def metro_hastings(niters: int, burnin: int,
theta: np.ndarray, proposal: callable,
target: callable):
thetas = np.zeros((niters - burnin, 2), np.float)
for i in range(niters):
new_theta = proposal(theta)
p = min(target(*new_theta) / target(*theta), 1)
if np.random.rand() < p:
theta = new_theta
if i >= burnin:
thetas[i - burnin] = theta
return thetas
init_theta = np.array([0.5, 0.5])
niters = 10000
burnin = 500
thetas = metro_hastings(niters, burnin, init_theta, proposal, target)
kde = gaussian_kde(thetas.T)
XY = np.vstack([X.ravel(), Y.ravel()])
posterior_metroplis = kde(XY).reshape(X.shape)
make_plots(X, Y, prior(X, Y), lik(X, Y), posterior_metroplis)
plt.title(f"M-H采样", fontsize=20)
plt.tight_layout(True)
plt.show()
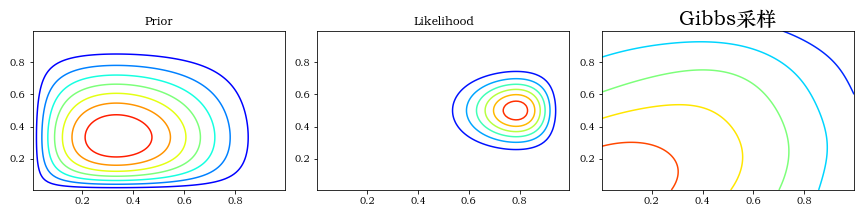
""" gibbs """
theta = np.array([0.5, 0.5])
niters = 10000
burnin = 500
def gibbs(niters: int, burnin: int,
theta: np.ndarray, proposal: callable,
target: callable):
thetas = np.zeros((niters - burnin, 2), np.float)
for i in range(niters):
theta = [beta(a + k1, b + N1 - k1).rvs(), theta[1]]
theta = [theta[0], beta(a + k2, b + N2 - k2).rvs()]
if i >= burnin:
thetas[i - burnin] = theta
return thetas
thetas = gibbs(niters, burnin, init_theta, proposal, target)
kde = gaussian_kde(thetas.T)
XY = np.vstack([X.ravel(), Y.ravel()])
posterior_metroplis = kde(XY).reshape(X.shape)
make_plots(X, Y, prior(X, Y), lik(X, Y), posterior_metroplis)
plt.title(f"Gibbs采样", fontsize=20)
plt.tight_layout(True)
plt.show()
|