Polyhedral Tutorials
关于Polyhedral Tutorials的一个中文翻译归档,其中所有章节原文位于我的仓库中.
import islpy as isl |
(Quasi) Affine Expressions
Quasi-affine表达式, 即通过常量、变量以及对应基础操作构成的表达式.
Base - Constants (\((c_i)\)) - Parameters (\((p_i)\)) - Variables (\((v_i)\))
Operations - Unary negation \(( (-e) )\) - Addition \(( ( e\_0 + e\_1 ) )\) - Multiplication by a constant \(( (c * e) )\) - Constant division \(( (e / c) )\) - Constant remainder \(( (e \mod c) )\)
Examples
Valid Expressions
- 42
- n, m
- i, j
- -i, 3 * i + 4
- i / 2, i % 3 ****
Invalid Expressions
- i * n, n * m
- 5 / n, i % j
Presburger Formula
Presburger 公式就是affine表达式进行二元关系组合:
Base - Boolean constants (⊤, ⊥)
Operations - Comparisions between quasi-affine expressions
\((e0 \oplus e1, \oplus \in)\) \(\{(<, \le, =, \ne, \ge, >) \}\)
Boolean operations between Presburger Formulas
\((e0 \otimes e1, \otimes \in)\) \(\{(\land, \lor, not, \Rightarrow, \Leftarrow, \Leftrightarrow ) \}\)
Quantified variables
\(( \exists x: p(x, ...) )\)
\(( \forall x: p(x, ...) )\)
Examples
Valid Expressions
- \(1 < 0\)
- \((j + 3 \le 0 \land 0 \le n)\)
Invalid Expressions
- 42
Presburger Sets
Presburger 集合S, 是一个通过Presburger公式定义的整数向量集合. 通常\(p\)作为Presburger公式会被执行为true, 然后\((\vec{v})\)则是集合包含的所有元素.
Basic Set
Basic Set 是 Presburger Set的最简单形式,仅允许描述单个凸(但可能是稀疏)集的 Presburger 公式.
集合的space被tuple的维度定义.一个集合包含pair被称为2维space.
Examples
以下两个基本集合 Triangle 和 Square :
Triangle: \((\{A[i,j] \mid 0 < i < j < 10\})\)
Square: \((\{ A[i,j] \mid 5 < i < 10 \land 0 < j < 5 \})\)
Triangle = isl.BasicSet("{A[i,j] : 0 < i < j < 10}") |

Sparse Basic Sets
这个例子中展示了集合中存在取模约束,这样集合元素会变成稀疏的.
Example
basic set Sparse 是排除某些对角线的正方形.
Sparse = isl.BasicSet("{A[i,j] : 0 < i,j < 10 and (i + j) % 3 != 0}") |

Exercises
- Plot a set UpperTriangle with a base of width 7.
x |
s = isl.BasicSet("{A[x,y] : 0 <= x < 7 and 0 <= y < 4 and y <= x < 7-y }") |
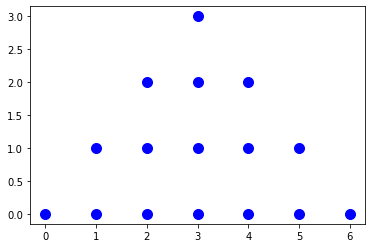
- Plot a set LowerTriangle with a base of width 7
x x x x x x x
x x x x x
x x x
x
s = isl.BasicSet("{A[x,y] : 0 <= x < 7 and -4 < y <= 0 and (-y) <= x < 7+y }") |
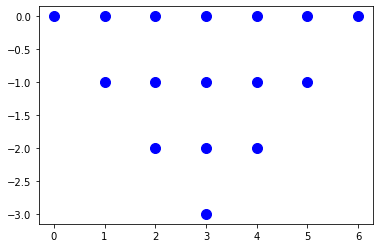
- Plot a set Diamond with a width and height of 7.
x
x x x
x x x x x
x x x x x x x
x x x x x
x x x
x
s = isl.BasicSet("{A[x,y] : 0 <= x < 7 and -4 < y < 4 and (-y) <= x < 7+y and y <= x < 7-y }") |
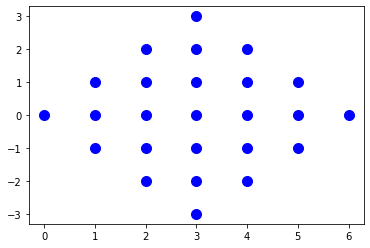
- Plot a set Parallelogram with a height of 4 and a
width of 7 with a slope of 1/2.
x x x x x x x
x x x x x x x
x x x x x x x
x x x x x x x
s = isl.BasicSet("{A[x,y] : 0 <= y < 4 and y <= x < y + 7 }") |
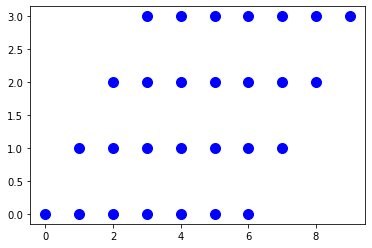
Sets
集合是有限的基础集合的联合, 他们都属于相同的named space中, 也就是他们的标识维度名都相同.
Combined = Triangle.union(Square) |
Combined: { A[i, j] : i > 0 and j <= 9 and (j > i or (6 <= i <= 9 and 0 < j <= 4)) }
Union Set
不同named spaces的有限集合组成的是union set.
u = isl.UnionSet("{A[i,j] : 0 < i,j and j + i < 10; B[i,j] : 5 <= i,j < 10 }") |

Presburger Relations
Presburger Relations 是一种映射关系, 将多个Presburger formula描述的set映射起来.
通常可以表示为M = \(( \{ \vec{v_1}
\rightarrow \vec{v\_2} \mid \vec{v\_1}, \vec{v\_2} \in \mathbb{Z}^n : p
(\vec{v\_1}, \vec{v\_2}, \vec{p})\} )\),其中p是一个
Presburger 公式, 如果元组对 \((\vec{v\_1})\) 和 \((\vec{v\_2})\) 是 M 的元素,
则计算结果为真.
Basic Map
basic map关联了basic set.
Example
比如下面关联set A和position X.
Translate = \((\{A[i,j] \rightarrow X[i+10,j+1]\})\)
To visualize this set, we use it to translate the earlier defined set Triangle. Without constraining Translate to Triangle the map is infinite and cannot be rendered.
from islplot.plotter import * |
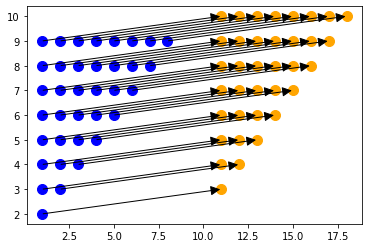
Polyhedral Representation
将一个命令式语言的statement作为identifer, 加上loop的约束, 将其转化为Union Set :
|
|
| ||
|
$ $ |
\(( \{ T[i,j] \mid 0 < i \le j < 10; S[i,0] \mid 0 < i \le 20 \})\) |
Statement instances
考虑以下计算多项式乘积的代码片段 每个多项式都由其系数数组表示
const int N = 100; |
为其中一些statement添加label作为identifier.
Statement S 初始化数组Z的元素,statement
T计算它们. Statement S
被包含在循环中,他将会按以下顺序被执行 \(((2\mathtt{N} + 1))\) 次:
Z[0] = 0.; /* i = 0 */Z[1] = 0.; /* i = 1 */- ...
Z[2*N] = 0. /* i = 2*N */;
把循环中每个单独执行的statement称为 statement instances 这样每个instance可以通过语句label和封闭循环迭代器的值来标识, 例如:
- \((\mathtt{S}(0))\)
- \((\mathtt{S}(1))\)
- ...
- \((\mathtt{S}(2 \mathtt{N}))\)
如果一个statement包含在多个循环中,
其instance由所有迭代器的值按循环的顺序来标识, 比如statement
T 会包含以下这些例子:
- \((\mathtt{T}(0,0))\) for
Z[0] += A[0] * B[0] /* i = 0, j = 0 */, - \((\mathtt{T}(0,1))\) for
Z[1] += A[0] * B[1] /* i = 0, j = 1 */, - ...
- \((\mathtt{T}(\mathtt{N},\mathtt{N}))\) for
Z[2*N] += A[N] * B[N] /* i = N, j = N */.
Iteration domain
一个statement的所有instance的集合被称为 (iteration) domain.
迭代域可以使用 set-builder 表示法来表示:
比如, \(( \mathcal{D}_\mathtt{S} = \{
\mathtt{S}[i] : 0 \leq i \leq \mathtt{N} \}. )\) 表达式 \(( 0 \leq i \leq \mathtt{N} )\)
被循环起始(i=0)到结束(i<=N)所约束.
注意, 这里 \(( \mathtt{N} )\) 被看作是符号常量. 在多面体模型中,这些符号常量通常被称为 (structure) parameters:
\(( \mathcal{D}\_\mathtt{S} = [N] \rightarrow \{ \mathtt{S}[i] : 0 \leq i \leq N \} )\), 本质上是将其转换为从参数值到domain set的具体instance的映射. 这样的参数集可以在 isl 中如下定义:
import islpy as isl |
[N] -> { S[i] : 0 <= i <= N }同样, 我们可以为statement T定义iteration domain, \(( \mathcal{D}_\mathcal{T} = [N] \rightarrow \{
\mathtt{T}(i,j) : 0 \leq i,j \leq N \} )\).
这个domain被定义为一组二维向量, 向量的每个分量都以嵌套顺序对应于一个封闭循环.
Question
使用 isl 表示定义变量 D_T 使其包含
T 的迭代域, 然后打印它.
D_T = isl.Set("[N] -> { T[i,j] : 0 <= i, j <= N }") |
[N] -> { T[i, j] : 0 <= i <= N and 0 <= j <= N }如上所示, isl 输出使用连词(logical and)来组合不同迭代器周围的不等式, 这可以很方便循环边界不同的情况.
Question
使用 and operator 分离 i 和
j的bounds来重新定义D_T .
D_T = isl.Set(" [N] -> { T[i, j] : 0 <= i <= N and 0 <= j <= N }") |
[N] -> { T[i, j] : 0 <= i <= N and 0 <= j <= N }注意, print的输出不一定再现输入的文本形式 相反, 它表示简化后的同一集合, 比如消除了多余的不等式, 并使用更简单的方程来表示出现在第一位的分量. 比如下面这个例子:
print(isl.Set("{[i,j]: i+j >= 0 and i >= 0 and j > 0 and j >= 1}")) |
{ [i, j] : i >= 0 and j > 0 and j >= -i }Handling Non-Unit Strides
考虑以下代码片段, 它取数组中的每个奇数元素的负数. const int N;
double A[2*N];
for (int i = 1; i < 2*N; i += 2)
R: A[i] = -A[i];
如果数组A存储的是复数的实部和虚部,
那么上面的代码操作计算复共轭.
R 的迭代域现在应该限制为 i 的奇数值,
这可以使用模运算符来实现:
$( _: [N] { [i] : 0 i < N i = 1 } $)
D_R = isl.Set("[N] -> {R[i]: (i mod 2) = 1 and 0 <= i < N}") |
[N] -> { R[i] : (1 + i) mod 2 = 0 and 0 <= i < N }isl 将模运算转换为带底舍入的除法, 这种转换是模运算的两个属性的组合
\(( a \mod b = c \Leftrightarrow (a + c) \mod b = 0 )\),
\(( a \mod b \equiv a - b \lfloor a/b \rfloor )\).
Question
在下面的代码中定义代表Q的迭代域的集合, 然后打印出来
const int N;
double A[2*N];
for (int i = 1; i < 2*N; i += 2)
Q: A[i] = -A[i];
D_Q = isl.Set("[N] -> {Q[i]: (i mod 2) = 1 and 0 <= i < N}") |
[N] -> { Q[i] : (1 + i) mod 2 = 0 and 0 <= i < N }Handling Conditions
循环内的条件构造也限制了它们所包含的语句的迭代域,
复共轭计算也可以使用单位步长循环内的分支语句来重写. const int N;
double A[2*N];
for (int i = 1; i < 2*N; ++i)
if (i % 2 == 1)
P: A[i] = -A[i];
迭代域的定义还应该包括语句周围的分支所施加的约束.
Question
定义代表P的迭代域的集合并打印它.
D_P = isl.Set("[N] -> {P[i]: (i mod 2) = 1 and 0 <= i < N}") |
[N] -> { P[i] : (1 + i) mod 2 = 0 and 0 <= i < N }即使 P 和 R 的语句实例集是相同的,
这些域也会被认为是不同的因为是不同的statement name.
Question
如何修改D_P, 让他等价于D_R?
D_P = isl.Set("[N] -> {R[i]: i mod 2 = 1 and 0 <= i < N}") |
TrueIteration Domains as Presburger Sets
由于isl在Presburger Sets上运行, 因此它可以编码任何可以使用Presburger公式表示的迭代域, 这通常涉及由具有所谓的static control flow的循环和分支包围的语句.
也就是说, loop bounds和分支条件是外部边界和参数的Presburger公式, 其中参数的值未知, 但在整个执行过程中必须保持不变.
作为推论, 控制流不能依赖于被计算的value, 因此, 适合多面体建模的程序部件被称为static control parts或SCoPs.
Question
定义包含在两个循环和一个具有析取约束的分支中的statement的迭代域.
Hint: 如果有必要, 请使用运算符or和括号来确保优先级
for (int i = 0; i < 10; ++i)
for (int j = 0; j < 10; ++j)
if (i < j - 1 || i > j + 1)
Z[i][j] = 0.;
D_Z = isl.Set(" { Z[i,j] : 0 <= i,j < 10 and (i < j - 1 or i > j + 1) } ") |
{ Z[i, j] : (i >= 0 and 2 + i <= j <= 9) or (i <= 9 and 0 <= j <= -2 + i) }也可以使用Presburger公式表达某些常见的数学运算:
i >= max(a,b)\(( \Leftrightarrow i \geq a \wedge i \geq b )\) (lower bound only)i <= min(a,b)\(( \Leftrightarrow i \leq a \wedge i \leq b )\) (upper bound only)a = ceil(b/c)\(( \Leftrightarrow a = \lfloor (b - 1)/c \rfloor + 1 )\)
Putting Domains Together
总之, statement的迭代域是一组受仿射表达式约束的多维向量, 仿射表达式出现在statement周围的循环边界和分支条件下.
由于statement名称不同, 多个语句的迭代域存在于不同的Spaces中,
即使它们被相同的循环包围, 通过将它们放入Union
set中可以统一操作, 比如组合domain: for (int i = 0; i < 10; ++i)
for (int j = 0; j < 10; ++j) {
if (i < j - 1)
S1: Z[i][j] = 0.;
if (i > j + 1)
S2: Z[i][j] = 0.;
}
被定义为: $( = {[i,j]: 0 i,j < 10 i < j - 1 } {[i,j]: 0 i,j < 10 i > j + 1 }, $)
isl表示如下:
D = isl.UnionSet("{S1[i,j]: 0 <= i,j <= 10 and i < j - 1; S2[i,j]: 0 <= i,j <= 10 and i > j + 1}") |
{ S2[i, j] : 0 <= i <= 10 and 0 <= j <= 10 and j <= -2 + i; S1[i, j] : 0 <= i <= 10 and j >= 2 + i and 0 <= j <= 10 }Plotting Iteration Domains
可以绘制1D/2D的非参数迭代域集合:
from islplot.plotter import * |

可视化可以有效的检查domain的size或者独立的domain交集.
这里例子中,domain完全不相交,意味他们可以被分离的循环所穿过.
如果domain是参数化的,我们首先需要fix所有的参数到constant, 通过以下几种方法:
- 创建一个参数集, 其中域值是固定的;
- 将domain与这个新set相交;
- 映射所有参数.
下面是对第一个例子的T statement 的操作方法:
fixer = isl.Set("[N] -> {T[i,j]: N = 5}") |

isl.dim_type.param表示你想映射的参数,
后面两个数据分别是第一个参数的位置和将要映射的连续参数的数量.
为了plot出来, 因此把所有维度都映射出来.注意, 如果忘记fix参数大小, 该集将变得unbounds, 无法plot.
与参数类似, 在plot之前可以投影domain dimensions获得两个维度. 使用'isl.dim_type.set'来获取这些
Question
下面执行LU分解的代码:
for (i = 0; i < N; i++) { |
- 为所有的iteration domain定义union set.
- 检查iteration domain
Sa和Sc是否有overlap - 绘制domain在(i,j)和(j,k)
Hint: 不能直接从union set中映射出domain dimension,因为他们可能存在不同的space中, 但是可以从set中做union得到他.
D_Sa = isl.Set("[N] -> { Sa[i,j,k] :0 <= k < j < i < N }") |
[N] -> { Sc[i, j, k] : i <= j < N and 0 <= k < i; Sa[i, j, k] : i < N and j < i and 0 <= k < j; Sb[i, j] : i < N and 0 <= j < i }# NOTE 这里需要去掉标识名再做交集. |
TrueD_Sa = D_Sa.intersect(isl.Set("[N] -> { Sa[i,j,k]: N = 8}")) |
D_Sa_ = D_Sa.project_out(isl.dim_type.set, 2, 1) |
{ [i, j] : (i <= 7 and 0 < j < i) or (i > 0 and i <= j <= 7); Sb[i, j] : i <= 7 and 0 <= j < i }
D_Sa_ = D_Sa.project_out(isl.dim_type.set, 0, 1) |
{ [j, k] : j <= 7 and 0 <= k < j }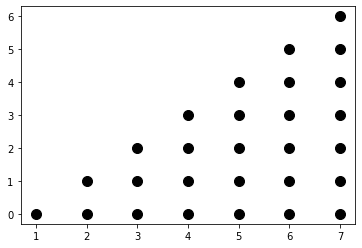
Schedules
$ { (i,j,k) (i+j, k, i) }$
Definition
statement的iteration domain给出了instances的执行信息,但是并没有指定执行顺序.
实际上, 我们可以通过为每个statement instance分配逻辑执行顺序来指定分段 quasi-linear 的顺序.
简而言之, 此schedule可以表示为statement instance和逻辑顺序之间的Presburger映射.
Identity Schedule
默认情况下, statement instances按照循环迭代顺序执行. 这可以使用identity schedule relation来表示.
比如一个简单的循环初始化: for (i = 0; i < N; ++i)
S: A[i] = 0.0;
iteration domain:
\(( \mathcal{D}\_\mathtt{S} = [N] \rightarrow \{ \mathtt{S}(i) : 0 \leq i < N \} )\)
对应的identity schedule:
\(( \mathcal{T}\_\mathtt{S} = [N] \rightarrow \{ \mathtt{S}(i) \rightarrow (t_0) : t_0 = i \} )\).
In isl notation:
import islpy as isl |
[N] -> { S[i] -> [t0 = i] }Multidimensional Schedules
如果一个statement instance由多个元素的向量标识, 则表示这个statement包含在多个嵌套循环中, 它通常映射到multidimensional逻辑顺序.
下面的例子中, statement instances以逻辑顺序的lexicographical order进行执行.
比如\(((0,42))\)在\(((100,0))\)之前, 写作\(((0,42) \prec (100,0))\).
lexicographical order通常扩展到比较不同大小的向量.
短的的向量, 是和较长向量的前缀比较, 例如\(((0,42) \prec (0,42,0))\).
比如, 多维下的初始化: for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
S: A[i][j] = 0.0;
iteration domain:
\(( \mathcal{D}_\mathtt{S} = [N] \rightarrow \{ \mathtt{S}(i): 0 \leq i,j < N \} )\)
identity schedule:
\(( \mathcal{T}_\mathtt{S} = [N] \rightarrow \{ \mathtt{S}(i,j) \rightarrow (t_0, t_1) : t_0 = i \wedge t_1 = j \} )\).
In isl notation:
D_S = isl.Set("[N] -> {S[i,j]: 0 <= i,j < N}") |
[N] -> { S[i, j] -> [t0 = i, t1 = j] }即使理论上schedule可以用单维度来表示:
\(( \mathcal{T}_\mathtt{S} = [N] \rightarrow \{ \mathtt{S}(i,j) \rightarrow (t_0) : t_0 = Ni + j \} )\)
但由于存在变量的乘法, 这种表达式是不能表示为Presburger映射的.
不过当使用实际常量而不是常量参数时, 是可以构建这样的schedule的.
Question
写出三维数组循环初始化的identity schedule for (i = 0; i < N; ++i)
for (j = 0; j < N; ++j)
for (k = 0; k < N; ++k)
T: A[i][j] = 0.0;
D_T = isl.Set("[N] -> { A[i,j,k] : 0 <= i,j,k < N }") |
Map("[N] -> { A[i, j, k] -> [t0 = i, t1 = j, t2 = k] }")Question
尝试为同一域定义一个具有乘法的一维计划(会出现错误).
try: |
got errorRepresenting Lexical Order
考虑一个循环中包含两个statement: for (i = 0; i < 10; ++i) {
P: A[i] = 0.0;
Q: B[i] = 1.0;
}
对两个statement使用简单的identity schedule将导致他们具有相同的执行顺序.
然而, 从代码中可以清楚地看出,
Q的是在P之后执行的, statement的lexical
order可以使用auxiliary维度在schedule中编码.
他分配一个常量,
以便在Q之前强制执行P的statement,
即P的常数小于Q的常数.
由于顺序存在于循环中内部, 因此辅助维度放置在循环维度之后.
\(( \mathcal{T} = \{ P(i) \rightarrow (t\_0, t\_1) : t\_0 = i \wedge t\_1 = 0 \} \cup \{ Q(i) \rightarrow (t\_0, t\_1) : t\_0 = i \wedge t\_1 = 1 \} )\)
这个map会将顺序\(((i,0))\)分配到P, 然后\(((i,1))\)分配到Q.
从而清晰的表示\(( \forall i, (i,0) \prec (i,1) )\)
isl中, 不同的 statements的schedules 可以被结合为 union map.
D = isl.UnionSet("{P[i]: 0 <= i < 10; Q[i]: 0 <= i < 10}") # 首先列出两个statement的set |
{ Q[i] -> [t0 = i, t1 = 1]; P[i] -> [t0 = i, t1 = 0] }考虑两个循环组成的SCoP
for (i = 0; i < 10; ++i) { |
这个例子中,所有的U的实例都在所有的V的实例之前执行,
因此辅助维度会在循环维度之前加入:
\(( \mathcal{T} = \{ \mathtt{U}(i) \rightarrow (t_0, t_1) : t_0 = 0 \wedge t_1 = i \} \cup \{ \mathtt{V}(i) \rightarrow (t_0, t_1) : t_0 = 1 \wedge t_1 = i \}. )\)
Or, in isl notation:
D2 = isl.UnionSet("{U[i]: 0 <= i < 10; V[i]: 0 <= i < 10}") # 两个statement分别的set |
{ U[i] -> [t0 = 0, t1 = i]; V[i] -> [t0 = 1, t1 = i] }绘制两个scheduled domain可以发现不同:
from islplot.plotter import * |
{ [t0, t1 = 1] : 0 <= t0 <= 9; [t0, t1 = 0] : 0 <= t0 <= 9 }
plot_set_points(D2.apply(S2)) |
{ [t0 = 1, t1] : 0 <= t1 <= 9; [t0 = 0, t1] : 0 <= t1 <= 9 }
注意, 因为上面将logical dates和所有statement的实例绘制在同一个space中,所以比较难辨认.
Question
通常,如果auxiliary dimension被statement共享, 那么定义在循环的最内部,
如果没有被任何loop共享, 那么放到最前面.
为下面的schedule定义auxiliary dimension:
for (i = 0; i < 10; ++i) { |
D = isl.UnionSet("{ S1[i,j] : 0 <= i < 10 and 0 <= j < 5 ; S2[i,j] : 0 <= i < 10 and 0 <= j < 5 }") |
{ S1[i, j] -> [t0 = i, t1 = 0, t2 = j]; S2[i, j] -> [t0 = i, t1 = 1, t2 = j] }Modeling memory accesses
Access Relations
每个statement instance可能会访问一个或多个的variables/ scalars/ arrays.
如果数组的下标索引是loop iterators 和 structure parameters的仿射形式, 那么可以定义Presburger relation来将statement instances和他们访问的数组元素关联起来. 为了简单起见,在polyhedral model中将scalar作为0维数组来表示.
考虑一个矩阵乘的算子: double X[100], Y[100], Z[200];
double zero = 0.;
for (int i = 0; i <= 200; ++i)
S: Z[i] = zero;
for (int i = 0; i <= 100; ++i)
for (int j = 0; j <= 100; ++j)
T: Z[i + j] += A[i] * B[j];
如果只使用句法术语, 可以称为statement S 访问 array
Z.
但是,对于每一个独立的instance\((
\mathtt{S}(i) )\) 只访问其中的一个元素Z[i].
这可以被编码为 \(( \{ \mathtt{S}(i) \rightarrow \mathtt{Z}(a): a = i \} )\).
进一步, 我们知道array
Z的size,因此可以定义额外的约束来避免index out of range.
\(( \{ \mathtt{Z}(a): 0 \leq a \leq 200 \} )\).
同时S的iteration domain为:
\(( \{ \mathtt{S}(i): 0 \leq i \leq 200 \} )\).
在access relation中加入了以上约束后, 我们可以将上述set和statement domain进行intersect.
import islpy as isl |
{ S[i] -> Z[a = i] : 0 <= i <= 200 }上面最终加入约束后的例子中并没有显式对\((a)\)的范围约束,因为存在了隐式的约束\((a = i)\),所以isl会简化最终的表示.
scalar不存在下标索引, 因此他们表示为0维的向量.
但是这个range依旧存在一个name, 比如用zero来表示.
\(( \{ \mathtt{S}(i) \rightarrow \mathtt{zero}(): 0 \leq i \leq 200 \} )\).
此时额外的\((i)\)的约束将从iteration
domain S中获取.
A_S_zero = isl.Map("{S[i] -> zero[]:}") # s访问zero的映射 |
{ S[i] -> zero[] : 0 <= i <= 200 }最终, 可以将不同数组的访问关系组合成一个描述语句所有访问的联合映射.
A_S = isl.UnionMap(A_S_Z).union(A_S_zero) |
{ S[i] -> Z[a = i] : 0 <= i <= 200; S[i] -> zero[] : 0 <= i <= 200 }因为我们想要区分reads 和 writes的顺序, 因此我们可以分离不同的access relations的unions.
有时候他们会同时触发, 在这里例子中就是一个statement同时读写相同的variable.
Question
定义map A_T_Z并联合statement T和array
Z:
A_T_Z = isl.Map(" { T[i,j] -> Z[a = i + j]} ") # T访问Z的relation. |
{ T[i, j] -> Z[a = i + j] }Question
分别定义A_T_reads and A_T_writes的union
map:
A_T_reads = isl.UnionMap(" { T[i,j] -> Z[a = i + j] ; T[i,j] -> A[a = i] ; T[i,j] -> B[a = j]} ") |
{ T[i, j] -> A[a = i]; T[i, j] -> Z[a = i + j]; T[i, j] -> B[a = j] }A_T_writes = isl.Map("{ T[i,j] -> Z[a = i + j] }") |
{ T[i, j] -> Z[a = i + j] }Detecting Out-of-Bounds Accesses
通过将iteration domain和array size 约束set进行结合,就可以检测出越界访问,
考虑如下代码:
double A[99]; |
其中的access relation表示为\(( a = i + 1 )\)
首先将 S的iteration domain
和他的数组A的range约束进行intersect.
返回的access relation中包含了所有的access instances, 也就是所有的statement instance和array 元素的pair.
从domain约束过的relation中减去这个relation得到的结果就是invalid accesses,
表示了所有越界访问的statement instance.
A_X_A = isl.Map("{X[i]->A[a]: a = i+1}") # X的access relation |
{ X[i] -> A[a = 1 + i] : 0 <= i <= 98 }
{ X[i = 99] -> A[a = 100] }在上面的例子中,statement instance \(X(99)\)
就对数组A执行了越界的访问,
这个可以通过将循环上界修改为i < 99来完成修复.
Question
验证修复后的结果是正确的, 即检查subtract后的集合为空.
A_X_A = isl.Map("{X[i]->A[a]: a = i+1}") # 首先定义访问关系 |
公式\((1 = 0)\)为false.
在Presburger sets表示中, 这被用于表示一个空的集合,但不丢失name和维度信息.
Potentially Dependent Instances
现在来定义inverse access relation, 即映射数组元素到每个访问了这个元素的statement instance.
首先获取原始的access relation:
\(( \mathcal{A}\_{\mathtt{S} \rightarrow \mathtt{Z}} = \{ \mathtt{S}(i) \rightarrow \mathtt{Z}(a): a = i \wedge 0 \leq a,i \leq 200 \} )\),
inverse access
relation被相同的约束定义的,但是交换了其中的domain和range.
\(( \mathcal{A}\_{\mathtt{S} \rightarrow \mathtt{Z}}^{-1} = \{ \mathtt{Z}(a) \rightarrow \mathtt{S}(i): a = i \wedge 0 \leq a,i \leq 200 \} )\).
isl can compute inverse relations using:
A_S_Z_inv = A_S_Z.reverse() |
{ S[i] -> Z[a = i] : 0 <= i <= 200 }
{ Z[a] -> S[i = a] : 0 <= a <= 200 }如果两个statement instances访问了相同的array element, 他们可能会互相干扰.
比如,第一个instance写入了值,然后后面第二个instance去读取他.
在没有volatile限定符的情况下,两个statement读取相同的元素是不会被干扰的.
将此定义转换为relations, 我们需要在访问相同数组元素的statement instances之间定义一个映射.
通过access relation, 我们知道statement instance访问了哪些元素.
使用inverse access relation,我们能知道哪些其他的 statement instances访问了数组元素.
结合这两个access relation和数组下标索引, 可以为我们提供潜在的statement instances之间的依赖关系(potentially dependent).
这可以通过access relation之间的组合来完成:
\(( \mathcal{X} \circ \mathcal{Y} = \{ \pmb{x} \rightarrow \pmb{y} \mid \exists \pmb{z} : (\pmb{x},\pmb{z}) \in \mathcal{X} \wedge (\pmb{z},\pmb{y}) \in \mathcal{Y} \} )\).
isl中可以使用apply range操作来进行access
relation之间的组合.
比如计算statement S访问相同元素Z的关系:
dep_S_Z = A_S_Z.apply_range(A_S_Z.reverse()) # A_S_Z 表示S访问数组Z的关系, A_S_Z_inv表示数组Z被S访问的关系. |
{ S[i] -> S[i' = i] : 0 <= i <= 200 }得到了statement instances集合S的map结果.
在这个例子中,本质上是一个恒等的关系, 因为\((i^\prime = i)\)是相等的.
这表示不同的S的instance实际访问的是不同的数组元素.
Question
定义关于instance
S访问标量zero的映射dep_S_zero:
dep_S_zero = A_S_zero.apply_range(A_S_zero.reverse()) |
{ S[i] -> S[i'] : 0 <= i <= 200 and 0 <= i' <= 200 }上面就可以发现S的每个实例都是相关关联的,
因为他们访问的都是同一个标量值.
不过目前他们只读取这个值, 并没有修改他, 因此是不会与其他的statement instance产生干扰.
Reads and Writes
通常,只有至少一次访问为write的时候才会被看作是潜在依赖.
因此,还是需要将read/write分离为不同的relation.
现在用一个更小的数据范围的例子来说明问题: double X[10], Y[10], Z[20];
for (int i = 0; i <= 20; ++i)
S: Z[i] = 0.;
for (int i = 0; i <= 10; ++i)
for (int j = 0; j <= 10; ++j)
T: Z[i + j] += A[i] * B[j];
NOTE 在isl中,复杂度取决于依赖的数量,而不是集合中的数据量.
由于union中的map可以存在于不同的空间中, 因此可以通过组合来自不同语句的单个access (union) map来定义所有读取和写入的映射.
Question
下面给出了每个单独的access relations,
定义整个SCoP的reads and writes union
map.
A_S_Z = isl.Map("{S[i]->Z[a]: a = i and 0 <= a,i <= 20}") # S 访问数组Z的 access relation |
writes = isl.UnionMap(A_S_Z).union(A_T_Z) # S写入Z[i], T写入Z[i+j] |
{ T[i, j] -> A[a = i] : 0 <= i <= 10 and 0 <= j <= 10; T[i, j] -> Z[a = i + j] : 0 <= i <= 10 and j >= 0 and -i <= j <= 20 - i and j <= 10; T[i, j] -> B[a = j] : 0 <= i <= 10 and 0 <= j <= 10 }
{ T[i, j] -> Z[a = i + j] : 0 <= i <= 10 and j >= 0 and -i <= j <= 20 - i and j <= 10; S[i] -> Z[a = i] : 0 <= i <= 20 }Selecting one Write
为了避免将read access与read access组合的情况,
我们必须确保reads不会同时出现在组合的两边:
\(( (\mathtt{reads} \circ \mathtt{writes}^{-1}) \cup (\mathtt{writes} \circ \mathtt{reads}^{-1}) \cup (\mathtt{writes} \circ \mathtt{writes}^{-1}) )\)
注意 writes在右边出现了两次, 因此可以将表达式简化为:
\(( ((\mathtt{reads} \cup \mathtt{writes}) \circ \mathtt{writes}^{-1}) \cup (\mathtt{writes} \circ \mathtt{reads}^{-1}) )\).
现在来计算union的第一部分:
reads_writes = reads.union(writes) |
{ S[i] -> S[i' = i] : 0 <= i <= 20; T[i, j] -> S[i' = i + j] : 0 <= i <= 10 and j >= 0 and -i <= j <= 20 - i and j <= 10; T[i, j] -> T[i', j' = i + j - i'] : 0 <= i <= 10 and j >= 0 and -i <= j <= 20 - i and j <= 10 and i' >= -10 + i + j and 0 <= i' <= 10 and i' <= i + j; S[i] -> T[i', j = i - i'] : 0 <= i <= 20 and i' >= -10 + i and 0 <= i' <= 10 and i' <= i }Question
计算整个union的第二部分:
right_part = writes.apply_range(reads.reverse()) # (writes ∘ reads⁻¹) |
{ S[i] -> T[i', j = i - i'] : i' >= -10 + i and 0 <= i' <= 10 and i' <= i; T[i, j] -> S[i' = i + j] : 0 <= i <= 10 and j >= 0 and -i <= j <= 20 - i and j <= 10; S[i] -> S[i' = i] : 0 <= i <= 20; T[i, j] -> T[i', j' = i + j - i'] : 0 <= i <= 10 and 0 <= j <= 10 and i' >= -10 + i + j and 0 <= i' <= 10 and i' <= i + j }Question:
现在单独计算连接读取相同元素的statement
instances的two_reads的relation:
two_reads = reads.apply_range(reads.reverse()) |
{ T[i, j] -> T[i', j' = i + j - i'] : 0 <= i <= 10 and 0 <= j <= 10 and i' >= -10 + i + j and 0 <= i' <= 10 and i' <= i + j; T[i, j] -> T[i' = i, j'] : 0 <= i <= 10 and 0 <= j <= 10 and 0 <= j' <= 10; T[i, j] -> T[i', j' = j] : 0 <= i <= 10 and 0 <= j <= 10 and 0 <= i' <= 10 }比较以上这些relation, 即使它们以不同的顺序打印,
union和left_part也完全相同.
print(union.is_equal(left_part)) |
True这里是因为在这个例子中left_part实际上就是right_part的一个子集,
因为T读写的都是相同的元素, 因此pair \(( \mathtt{S}(i) \rightarrow
\mathtt{T}(i',j=i-i') )\)
print(right_part.is_subset(left_part)) |
True因此,我们不能只计算潜在依赖statement pair的整体集合,然后减去那些有两次reads的集合. 如果其中出现两次相同的write的关系,就会被抵消.
Question
使用read和write的statement instance pair之间的relation, 从中减去
two_reads 并检查它确实只是 union
的一个子集.
all_pairs = reads_writes.apply_range(reads_writes.reverse()) |
False
TrueVisualizing Potentially Dependent Instances
现在把限制只放在T的实例上
T_only = isl.Map("{ T[i,j] -> T[i',j']: }") # 过滤出访问点. |
{ T[i, j] -> T[i', j' = i + j - i'] : 0 <= i <= 10 and 0 <= j <= 10 and i' >= -10 + i + j and 0 <= i' <= 10 and i' <= i + j }
如上图所示, 每个statement instance都与 他自己 以及同一对角线上的一个或多个instance相关.
Question
定义一个map left_42 只包含 \((\mathtt{T}(4,2) )\) 在左边的pair,
和一个map right_42, 它只包含它在右边的pair
提示:map domain和range是集合, 可以对其进行操作
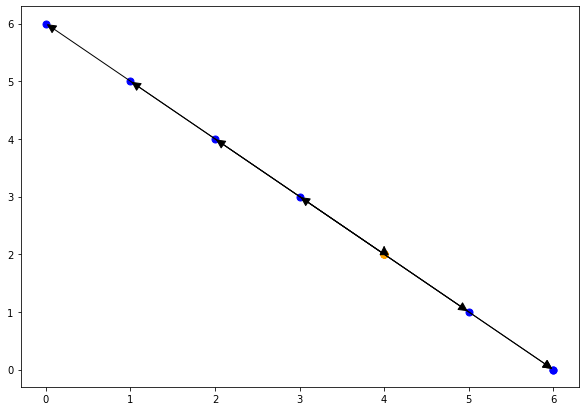
left_42 = union.intersect_domain(isl.Set("{ T[i = 4,j = 2] }")) |
{ T[i = 4, j = 2] -> S[i' = 6]; T[i = 4, j = 2] -> T[i', j' = 6 - i'] : 0 <= i' <= 6 }
{ T[i, j = 6 - i] -> T[i' = 4, j' = 2] : 0 <= i <= 6; S[i = 6] -> T[i' = 4, j = 2] }从图上比较这些relation:
plt.figure(figsize=(10, 7)) |
plt.figure(figsize=(10, 7), dpi=80) |
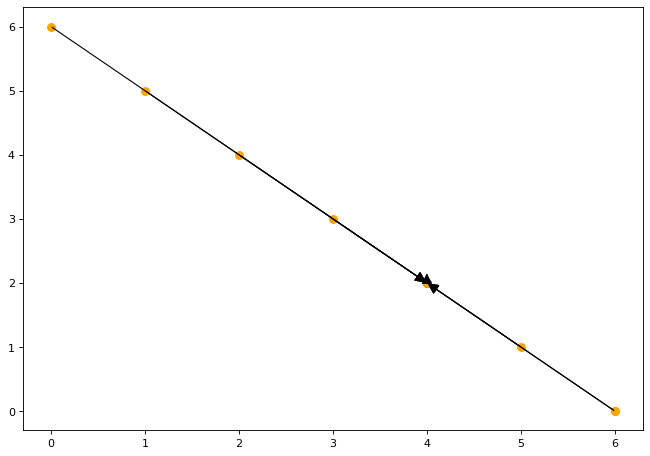
从上图可以看出, 两个relation是相同的.
这又是因为对 Z[i+j] 的唯一访问是read和write.
statement instance被连接到了访问相同数据的所有其他statement instance.
但是, 它并不一定会创建依赖. 例如, 依赖于自身并不完全有意义. 对于两个依赖的statement instance, 其中一个应该在另一个之前执行. 也就是说, 第一个statement要么生成第二个statement所需的一些数据, 要么使用一些将被第二个statement覆盖的数据. 依赖计算需要知道statement执行的顺序.
Question
给定以下代码, 计算和可视化访问相同数组元素的statement pair, 并且至少其中一个访问是write.
Hint: 使用disjunction对同一数组的不同引用中的不同下标进行编码.
for (i = 0; i < 6; ++i) |
# step 1. 定义每个statement instance的domain |
{ S1[i, j] -> S2[i' = 7 + i, j' = 11 + j] : 0 < i <= 5 and 0 <= j <= 3; S1[i, j] -> S2[i' = 8 + i, j' = 10 + j] : 0 <= i <= 4 and 0 < j <= 4 }plt.figure(figsize=(10, 7), dpi=80) |
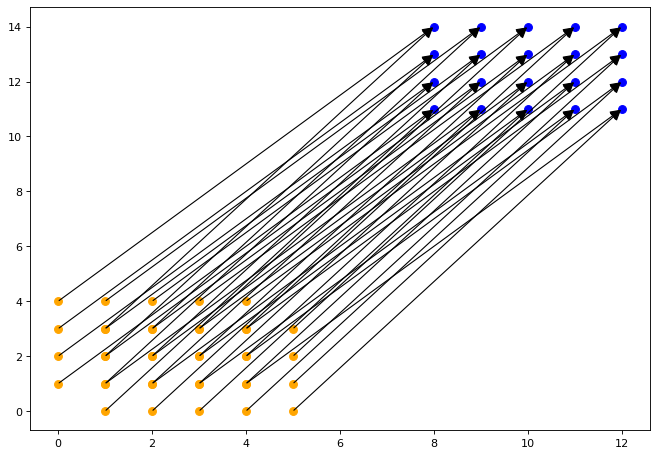
Question
选择 S1 和 S2 的 sample 实例,
并绘制访问同一数组元素的其他语句的实例.
point_22 = isl.Set("{S1[i,j]: i = 2 and j = 2}") # S1 写入X[2,2] |
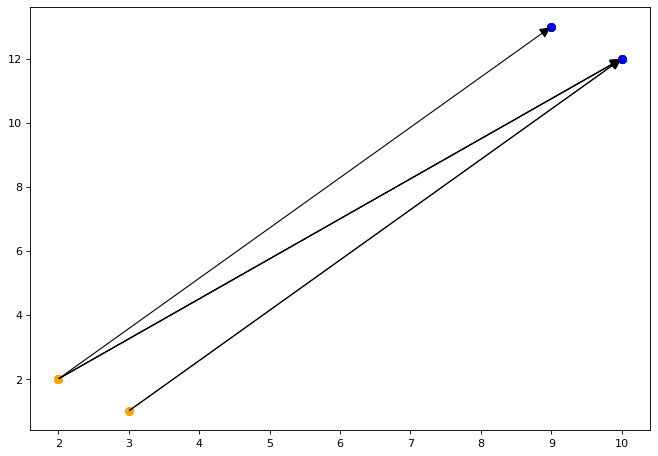
Dependence Analysis
当程序被转换时,保留程序语义的关键在于确保相同的值以相同的顺序写入和读取内存.
传统上,这是使用data dependences来表示的, 它对程序施加了部分执行顺序约束. 多面体模型的强大之处在于它能够在statement instance级别计算精确的data dependences.
如果一个statement instances在另一个statement instances之前执行, 则两个语句实例被称为依赖, 它们访问相同的数组元素, 并且至少一个访问权限写入该元素.
在Schedules章节中, 我们学习了如何定义statement
instance的执行顺序. 在Memory Access章节中,
我们定义了potentially dependent的statement instance的关系,
即访问了相同的数组元素并且至少一个访问是写入.
最简单的依赖分析就是将两部分结合起来,
首先我们给出一个多项式乘积的kernel: double A[10], B[10], Z[20];
for (int i = 0; i <= 20; ++i)
S: Z[i] = 0.;
for (int i = 0; i <= 10; ++i)
for (int j = 0; j <= 10; ++j)
T: Z[i + j] += A[i] * B[j];
然后定义对应的domain/schedule/access relations:
import islpy as isl |
我们还可以计算访问相同数组元素的statement instance pair集合.
Plugging in Schedule Information
因为statement instances是按照它们各自词典序执行的, 因此我们需要一种在relation中表达它的方法.
最简单的例子就是强制所有的statements的schedule都在相同的space中,
比如我们添加一个辅助维度\((t\_2)\)到schedule
S的statement T中
isl
允许我们定义lexicographic less-than的映射:
schedule_space = isl.Set("{[t0,t1,t2]:}").get_space() |
{ [t0, t1, t2] -> [t0', t1', t2'] : t0' > t0; [t0, t1, t2] -> [t0' = t0, t1', t2'] : t1' > t1; [t0, t1, t2] -> [t0' = t0, t1' = t1, t2'] : t2' > t2 }上面的map按照词典序的定义执行, 先比较第一对元素,如果一个在另一个之前, 则顺序成立. 否则假设它们相等并比较第二对, 继续直到最后一对.
precedes relation
即前一个词典上在后一个之前成对元组的集合.
Question
将 schedule 应用到 domain
以便将其映射到调度空间, 将结果保存为 scheduled_domain.
scheduled_domain = domain.apply(schedule) |
{ [t0 = 1, t1, t2] : 0 <= t1 <= 10 and 0 <= t2 <= 10; [t0 = 0, t1, t2 = 0] : 0 <= t1 <= 20 }现在我们知道如何将relation从domain空间移动到schedule空间: 将schedule relation apply到domain空间中的所有内容上.
Question
检查 \(( \mathtt{S}(2) )\) 在 \(( \mathtt{T}(0,0) )\) 之前执行.
Hint 1: 在两个instances之间定义映射.
Hint 2: 在schedule space中,可以检查relation是否是precedes的子集.
rel = isl.UnionMap("{S[i] -> T[a,b]: i = 2 and a = 0 and b = 0}") # 构造出对应循环点的instance. |
{ [t0 = 0, t1 = 2, t2 = 0] -> [t0' = 1, t1' = 0, t2' = 0] }
TrueMemory-based Dependence Analysis
Flow Dependences
当数组元素首先由一个statement instance 写入然后由另一个statement
instance 读取时, 就会出现数据流依赖性, 必须首先执行writer
instance.
因此, 我们首先将左侧的 writes union map与右侧的反向
reads union map组合在一起, \((
\mathtt{writes} \circ \mathtt{reads}^{-1} )\).
然后我们将其转换为schedule space, 并将结果与schedule space中的词典序relation相交, 从而 只保留依赖 source(第一个时间点)在其 sink(第二个时间点)之前执行的对.
dep_flow = writes.apply_range(reads.reverse()) # 获取潜在依赖 |
{ [t0 = 1, t1, t2] -> [t0' = 1, t1', t2' = t1 + t2 - t1'] : 0 <= t1 <= 10 and 0 <= t2 <= 10 and t1' >= -10 + t1 + t2 and t1' > t1 and 0 <= t1' <= 10 and t1' <= t1 + t2; [t0 = 0, t1, t2 = 0] -> [t0' = 1, t1', t2' = t1 - t1'] : t1' >= -10 + t1 and 0 <= t1' <= 10 and t1' <= t1 }由此产生的relation是在执行时间点之间,而不是在点之间. 要将其转换回domain space,重新调用一下relation可以很容易地反转. 即反向schedule relation将执行时间点映射到statement instances.
dep_flow = dep_flow.apply_domain(schedule.reverse()).apply_range(schedule.reverse()) # 再将其反向映射到数据点上, |
{ T[i, j] -> T[i', j' = i + j - i'] : 0 <= i <= 10 and 0 <= j <= 10 and i' >= -10 + i + j and i' > i and 0 <= i' <= 10 and i' <= i + j; S[i] -> T[i', j = i - i'] : i' >= -10 + i and 0 <= i' <= 10 and i' <= i }现在得到了 T 的不同instance之间的依赖关系,
我们可以分析它并与 potentially 依赖语句关系进行比较.
dep_flow_T = dep_flow.intersect(isl.UnionMap("{T[i,j]->T[i',j']:}")) |
from islplot.plotter import * |
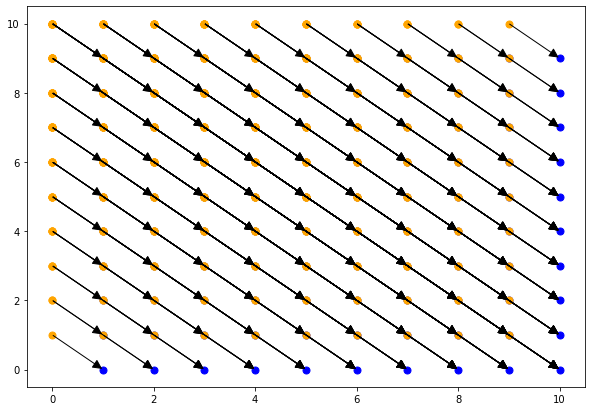
plt.figure(figsize=(10,7)) |

实际上每个statement instance是不能在其自身之前被执行, 因此观察到statement instances的self-dependences消失了.
Question
绘制instance $ (4,2) $ instance 的依赖 samples, 即它所依赖的statement instances和依赖它的statement instances.
point = isl.Set("{T[i,j]: i = 4 and j = 2}") # 添加instance point约束 |
{ T[i, j = 6 - i] -> T[i' = 4, j' = 2] : 0 <= i <= 3 }
{ T[i = 4, j = 2] -> T[i', j' = 6 - i'] : 5 <= i' <= 6 }# sources : 4 + 2 = 6, 他依赖于 [0,6], [1,5], [2,4], [3,3] 这些instance. |
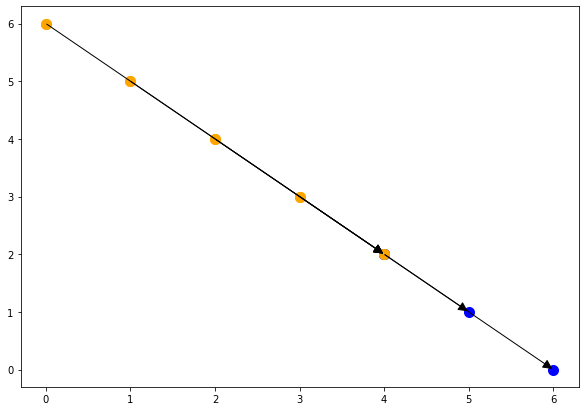
现在可以看到依赖于给定statement instances的实例都是访问相同数组元素并在它之前执行的实例, 类似地, 在给定statement instances之后执行的语句实例依赖于它.
Anti and Output Dependences
Anti-dependences是flow dependencs的reverse,即先读后写, 考虑Anti-dependences意味着在读取之前不覆盖他的值, Output dependences,或写后再写,需要保留写的顺序.
这些通常都被称为 false dependences,因为 sink 实例实际上并不 依赖 source 语句实例产生的 data, 而是需要在后面执行以避免干扰其他实例.
false dependences的 sink 通常是写访问,而source可以是读或写, 因此我们将左侧的读写union与右侧的reverse写组合:
\(( (\mathtt{reads} \cup \mathtt{writes}) \circ \mathtt{writes}^{-1} )\).
dep_false = writes.union(reads).apply_range(writes.reverse()) |
{ T[i, j] -> T[i', j' = i + j - i'] : 0 <= i <= 10 and 0 <= j <= 10 and i' >= -10 + i + j and i' > i and 0 <= i' <= 10 and i' <= i + j; S[i] -> T[i', j = i - i'] : i' >= -10 + i and 0 <= i' <= 10 and i' <= i }在这个例子中,false dependences与flow
dependences完全对应,因为S只写入,而T只读取和写入相同的元素.
实际上一般情况并非如此.
print(dep_false.is_equal(dep_flow)) |
TrueQuestion: Input Dependences
即使input 或连续读取通常不被强制执行, 但这个得到他们的依赖关系在程序优化中也很有用. 因此与前两种情况类似地计算input dependences:
dep_input = reads.apply_range(reads.reverse()) # 获得reads after reads的map |
{ T[i, j] -> T[i', j' = i + j - i'] : 0 <= i <= 10 and 0 <= j <= 10 and i' >= -10 + i + j and i' > i and 0 <= i' <= 10 and i' <= i + j; T[i, j] -> T[i' = i, j'] : 0 <= i <= 10 and 0 <= j <= 10 and j' > j and 0 <= j' <= 10; T[i, j] -> T[i', j' = j] : 0 <= i <= 10 and 0 <= j <= 10 and i' > i and 0 <= i' <= 10 }Input dependence看起来和flow dependence/false dependence不同,
其中只出现了T的实例,
这是因为S从来没有读过任何值.
Question
绘制input dependence的samples:
point = isl.Set("{T[i,j]: i = 4 and j = 2}") |
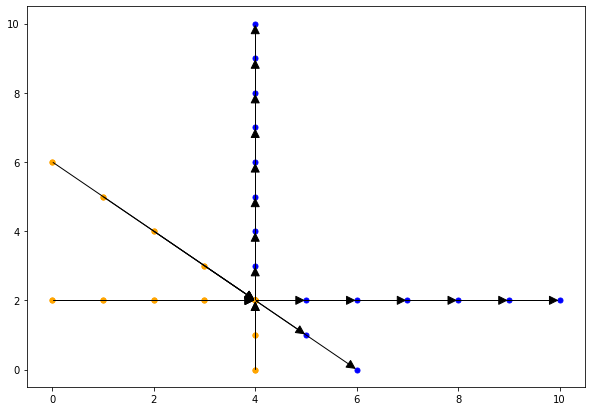
复杂的依赖pattern会导致同一个statement instance从多个不同的array读取数据.
Value-based Analysis
可以观察到每个statement
instance依赖了所有访问相同数组元素的实例,但是其实并不是必要的.
比如T(4,2)和T(5,1)的flow dependence:
point1 = isl.Set("{T[i,j]: i = 4 and j = 2}") |
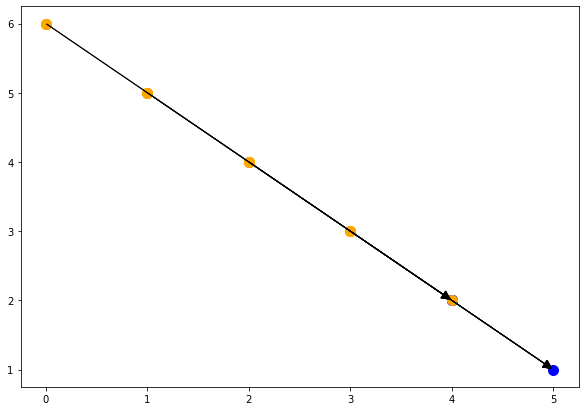
其中T(5,1)
依赖T(4,2)所依赖的所有实例以及T(4,2)本身.
print(sources2.domain().subtract(point1).is_equal(sources1.domain())) # 检查是否是子集. |
True如果将T(4,2)调度到T(3,3)之后,
那么T(5,1)也需要被调度到T(4,2)之后,
然后T(5,1)也需要调度到T(3,3)之后.
所以这两个实例之间的依赖关系transitively
covered(传递地覆盖)其他实例之间的依赖.
我们可以安全地移除传递覆盖的flow dependence. 通过计算词典序最大的source instance对于任意sink instance的依赖,然后删除其他的source instance来完成.
但以上的计算是non- trivial的,并且可能涉及到线性优化问题的求解, isl提供了value-based分析的功能. 但是,它会使用更加精确的树结构来调度, 对于这个例子, 我们将直接提供这个schedule:
schedule = isl.Schedule('{ domain: "{ T[i, j] : 0 <= i <= 10 and 0 <= j <= 10; S[i] : 0 <= i <= 20 }", child: { sequence: [{ filter: "{ S[i] }", child: { schedule: "[{S[i] -> [(i)]}, {S[i] -> [(0)]}]" }}, { filter: "{ T[i, j] }", child: { schedule: "[{T[i, j] -> [(i)]}, {T[i, j] -> [(j)]}]" }} ] } }') |
现在可以来进行value-based的依赖分析:
uai = isl.UnionAccessInfo.from_sink(reads) |
{ S[i] -> T[i' = -10 + i, j = 10] : 10 <= i <= 20; S[i] -> T[i' = 0, j = i] : 0 <= i <= 9; T[i, j] -> T[i' = 1 + i, j' = -1 + j] : 0 <= i <= 9 and 0 < j <= 10 }现在依赖关系已经不再包含transitively covered的例子了.
Question
将依赖关系限制在T上, 然后绘制T(4,2) 和
T(5,1)的samples,
并将他们memory-based的分析结果进行比较.
dep_flow_precise_T = dep_flow_precise.intersect(isl.UnionMap("{T[i,j]->T[i',j']:}")) |
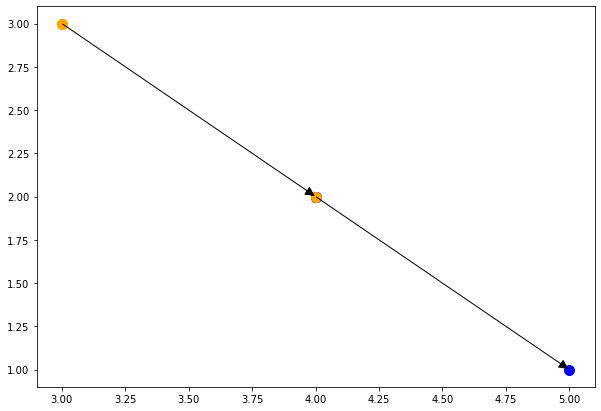
可以发现,每个T的实例限制只依赖一个其他T的实例.
Memory-based dependences可以通过计算依赖关系的transitive closure来从value-based dependences恢复出来:
Question
使用value-based的过程计算input dependences, 并且可视化:
uai = isl.UnionAccessInfo.from_sink(reads) |
{ T[i, j] -> T[i' = i, j' = 1 + j] : 0 <= i <= 10 and 0 <= j <= 9; T[i, j] -> T[i' = 1 + i, j' = j] : 0 <= i <= 9 and 0 <= j <= 10; T[i, j] -> T[i' = 1 + i, j' = -1 + j] : 0 <= i <= 9 and 0 < j <= 10 }dep_flow_precise_T = dep_flow_precise.intersect(isl.UnionMap("{T[i,j]->T[i',j']:}")) |
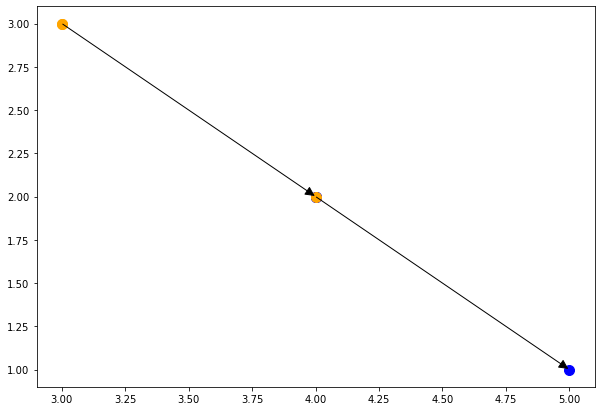
Classical Loop Transformations
Setup AST generation infrastructure
import islpy as isl |
Loop Reversal
循环反转可以改变循环元素被访问的方向, 反转之后, 之前迭代的第一个元素将会被最后执行, 最后一个元素将会被第一个执行.
Benefits:
- 可以被用来缩短依赖
domain = isl.UnionSet("[n] -> {S[i] : 0 <= i < n}") # 原始迭代域 |
for (int c0 = 0; c0 < n; c0 += 1)
S(c0);
for (int c0 = -n + 1; c0 <= 0; c0 += 1)
S(-c0);
Loop Fusion
之前分离在两个不同循环的中的statement将会被放到同一个循环中.
Benefits:
- 提高数据局部性
domain = isl.UnionSet("[n] -> {S[i] : 0 <= i <= n; T[i] : 0 <= i <= n}") # 原始两个循环, S和T |
{
for (int c1 = 0; c1 <= n; c1 += 1)
S(c1);
for (int c1 = 0; c1 <= n; c1 += 1)
T(c1);
}
for (int c0 = 0; c0 <= n; c0 += 1) {
S(c0);
T(c0);
}
Loop Fission (Loop Distribution)
Loop fission 是指将在同一个循环中执行的statement分配到两个不同的循环中去.
Benefits:
- 减少寄存器压力(在同一个循环中就意味着使用更多的寄存器存储数组地址/索引等)
- 可以开启其他的优化,
比如一个循环中只有一个statement可以进行
SIMDization,此时可以将其分离出去单独进行并行化.
domain = isl.UnionSet("[n] -> {S[i] : 0 <= i <= n; T[i] : 0 <= i <= n}") |
for (int c0 = 0; c0 <= n; c0 += 1) {
S(c0);
T(c0);
}
{
for (int c1 = 0; c1 <= n; c1 += 1)
S(c1);
for (int c1 = 0; c1 <= n; c1 += 1)
T(c1);
}
Loop Interchange
循环顺序交换
domain = isl.UnionSet("[n,m] -> {S[i,j] : 0 <= i <= n and 0 <= j <= m }") |
for (int c0 = 0; c0 <= n; c0 += 1)
for (int c1 = 0; c1 <= m; c1 += 1)
S(c0, c1);
for (int c0 = 0; c0 <= m; c0 += 1)
for (int c1 = 0; c1 <= n; c1 += 1)
S(c1, c0);
Strip Mining
Strip mining是将单个循环按chunk分离为两个循环, 外循环在每个blocks上迭代, 内循环在每个block内部进行迭代.
Benefits:
- 构建loop tiling和unroll-and-jam的block
domain = isl.UnionSet("{S[i] : 0 <= i < 1024 }") |
for (int c0 = 0; c0 <= 1023; c0 += 1)
S(c0);
for (int c0 = 0; c0 <= 255; c0 += 1)
for (int c1 = 0; c1 <= 3; c1 += 1)
S(4 * c0 + c1);
Loop Tiling
loop tiling是将多维循环切分为group,即tile. 首先一组外部循环在外部循环在所有的tile上迭代, point loops则在每个tile的points上迭代.
Benefits:
- 增加数据局部性
- 更加粗粒度的并行
domain = isl.UnionSet("{S[i,j] : 0 <= i,j < 1024 }") |
for (int c0 = 0; c0 <= 1023; c0 += 1)
for (int c1 = 0; c1 <= 1023; c1 += 1)
S(c0, c1);
for (int c0 = 0; c0 <= 255; c0 += 1)
for (int c1 = 0; c1 <= 3; c1 += 1)
for (int c2 = 0; c2 <= 255; c2 += 1)
for (int c3 = 0; c3 <= 3; c3 += 1)
S(4 * c0 + c1, 4 * c2 + c3);
Unroll-and-jam
Unroll-and-jam是将外部循环进行strip-mining分离为tile和point 循环,然后交换point loop和最内层的循环.
Benefits:
- 使得外部循环向量化.
domain = isl.UnionSet("{S[i,j] : 0 <= i,j < 1024 }") |
for (int c0 = 0; c0 <= 1023; c0 += 1)
for (int c1 = 0; c1 <= 1023; c1 += 1)
S(c0, c1);
for (int c0 = 0; c0 <= 255; c0 += 1)
for (int c1 = 0; c1 <= 1023; c1 += 1)
for (int c2 = 0; c2 <= 3; c2 += 1)
S(4 * c0 + c2, c1);
Skewing
倾斜迭代域
Benefits: - 使得部分无依赖的statement得以并行化.
domain = isl.UnionSet("[n] -> {S[i,j] : 0 <= i,j < n }") |
for (int c0 = 0; c0 < n; c0 += 1)
for (int c1 = 0; c1 < n; c1 += 1)
S(c0, c1);
for (int c0 = 0; c0 < n; c0 += 1)
for (int c1 = c0; c1 < n + c0; c1 += 1)
S(c0, -c0 + c1);
AST Generation
|
|
| ||
|
Iteration Domain $ { T[i,j] < i j < 10; S[i,0] < i }$
Schedule $ { T[i,j] ; S[i,0] }$ |
$ $ |
|
Polyhedral AST generation is more than scanning polyhedra
Generate an AST
Define a simple polyhedral program description
import islpy as isl |
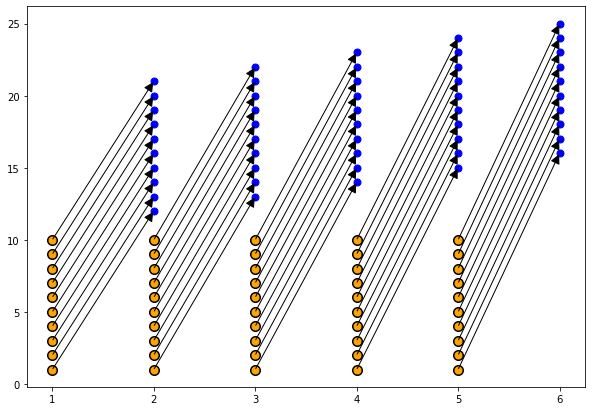
Translate polyhedral program description to an AST
最终生成的AST是实际的AST, 可以通过树操作对其进行遍历和检查.
|
build = isl.AstBuild.from_context(context) |
for (int c0 = 2; c0 <= 6; c0 += 1)
for (int c1 = c0 + 10; c1 <= c0 + 19; c1 += 1)
S(c0 - 1, -c0 + c1 - 9);
AST Generation for Constraint Sets
通常只有当满足特定条件时才可以使用一些transformation优化程序, 要始终实施这种优化方式的话, 那么需要将代码分为不同版本, 当满足特定条件时执行优化后的代码, 否则执行非优化的代码.
一个简单的例子:
void foo(long n, A[][100]) { |
这个代码代码当j小于100时会有更简单的依赖,
也就是要求n<100.
那么就可以使用如下的方法来保证优化后不出错误.
void foo(long n, A[][100]) { |
isl的AST generator允许生成任意来自isl的约束bool条件集合.
A simple constraint set
condition = isl.Set("[n] -> {: n < 100}") |
n <= 99Recovery of modulo expressions
condition = isl.Set("[n, m] -> {: n % 100 = 2}") |
(n - 2) % 100 == 0Verification of complex conditions
condition = isl.Set("[n, m] -> {: (n != 0 implies m = 5) or n + m = 42}") |
m == 5 || n == 0 || n + m == 42Parse C Code
需要手动编译安装pet库.
import pet |
[N] -> { : -2147483648 <= N <= 2147483647 }
{ domain: "[N] -> { S_0[i] : 0 <= i < N }", child: { schedule: "[N] -> L_0[{ S_0[i] -> [(i)] }]" } }
[N] -> { S_0[i] -> B[-1 + i] : 0 < i < N; S_0[i = 0] -> B[-1 + N] : N > 0 }
[N] -> { S_0[i] -> A[i] : 0 <= i < N }print(context) |
[N] -> { : -2147483648 <= N <= 2147483647 }print(schedule) |
{ domain: "[N] -> { S_0[i] : 0 <= i < N }", child: { schedule: "[N] -> L_0[{ S_0[i] -> [(i)] }]" } }print(reads) |
[N] -> { S_0[i] -> B[-1 + i] : 0 < i < N; S_0[i = 0] -> B[-1 + N] : N > 0 }print(writes) |
[N] -> { S_0[i] -> A[i] : 0 <= i < N }