roofline Model
学习一下roofline Model相关内容.
NERSC中给出了很好的说明. 这里就记录一些我想知道的问题.
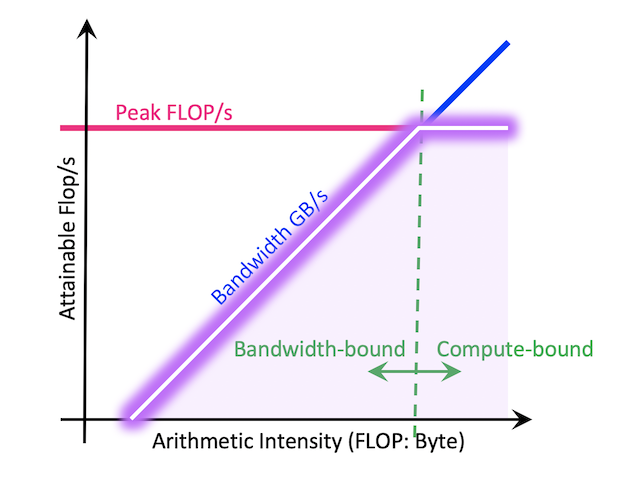
1. 纵坐标Performance
Performance是硬件的理论算力, 每秒浮点运算(FLOPS, flops or flop/s)
\[ \begin{align} FLOPS = \frac{FLOPs}{second} * cores \end{align} \]
2. 横坐标Arithmetic Intensity
Arithmetic Intensity是算力除带宽\(\frac{FLOPS}{byte}\).
3. 带宽线
左侧的斜线为带宽线, 考虑到横坐标为算力除带宽, 那么也就是在纵坐标算力固定的情况下, 带宽越大, 横坐标越小, 也就是斜率越高.
4. 绘制理论算力点
- 确定任务的计算量和访存量,从而计算出任务的算术强度
- 在roofline model上用一个点表示任务的算术强度和性能
- 比较任务的性能和roofline model的曲线,判断任务是受限于计算还是受限于带宽
- 如果任务的点在曲线下方,说明任务没有达到计算平台的最大性能,可以通过优化提高性能.如果任务的点在曲线上方,说明任务已经达到计算平台的最大性能,无法进一步提高性能.
5. 绘制实际算力点
如果你得到了任务的实际执行时间,你可以用它来计算任务的性能,然后在roofline model中绘制一个点表示任务的算术强度和性能. 具体步骤如下:
- 假设你知道任务的计算量(浮点运算次数或整数运算次数)和访存量(内存交换字节数),以及任务的实际执行时间(秒)
- 用计算量除以访存量,得到任务的算术强度
- 用计算量除以执行时间,得到任务的实际性能
- 参考4中的方法进行绘制
6. 存在多个级别的存储
对于每个任务统计他在各个级别上的访存量, 然后统计计算/内存移动并行时的最大时间作为理想时间.
\(T_{ideal} = max(M_{L1} / B_{L1},\ M_{L2}
/ B_{L2},\ FLOPs / FLOPs)\)
其中B为带宽,M为访存量.
这个时候就可以看到当前任务是被哪个级别的带宽限制住了,或者被哪个级别的算力限制住了.
7. MACs 与 FLOPs
MACs(Multiply–accumulate operations), FLOPs(floating operations). 如果目前的硬件是包含FMA(a <- a + (b x c))指令的话, 那么在计算乘加的时候, MACs会比FLOPs小一倍.