pytorch-lighting隐藏的坑
最近发现pytorch-lighting比较好用,比我在tensorflow里面自己写的那个好,不过因为他的结构嵌套的比较深,用起来还是会踩坑。这里来记录一下。
最近发现pytorch-lighting比较好用,比我在tensorflow里面自己写的那个好,不过因为他的结构嵌套的比较深,用起来还是会踩坑。这里来记录一下。
尝试用了一下mindspore,这里给出一个dcgan的demo对比一下两个框架。
我使用mindspore 0.7,tensorflow 2.2,megengine 0.6,其他参数均相同。
感觉生了个病八月份就要过去了。。。难受。生病的就很想休息,一点也不想学习,然而一休息就半个月没了😔,又感觉自己浪费了宝贵的时间。这次我主要总结一下生病的情况,因为其实从过年开始就有症状了,但后面去医院医生居然看不出我是什么病,导致暑假里面吃了不该吃的东西让病情严重了。
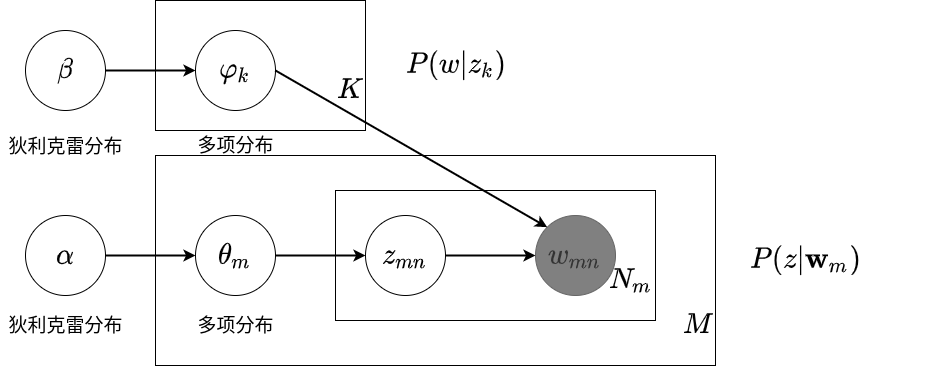
潜在狄利克雷分配模型其实就是一个确定结构的概率图模型,他主要做两件事情:
学习到话题的单词分布\(p(w|z_k)\),意为给定对应话题得到对应的单词.
学习到文本的话题分布\(p(z|\mathbf{w}_m)\),意为给定对应文本得到对应的话题.
如下图所示:
\(\varphi_k\sim \text{Dir}(\beta)\)控制了多项分布\(p(w|z_k)\)根据主题随机生成当前文本下的单词分布\(\mathbf{w}\).
\(\theta_{m}\sim \text{Dir}(\alpha)\)控制了多项分布\(p(z|\mathbf{w}_m)\)根据当前文本得到所对应主题的概率分布.