Halide 入门
Halide快速入门笔记。
基础概念
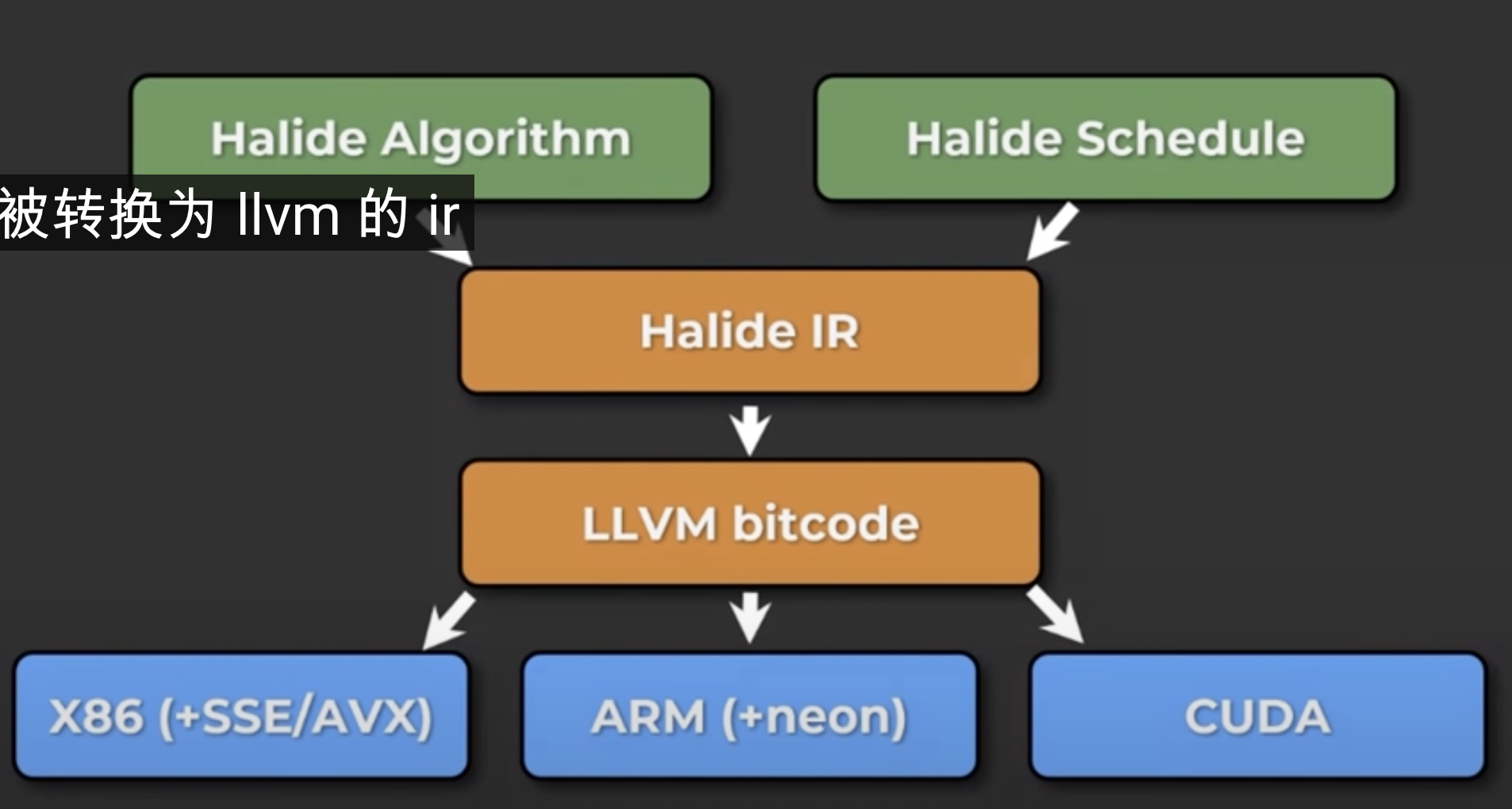
halide是一个抽象语言,他通过运算过程描述以及运算优化描述生成halide的IR,然后使用llvm库生成多个平台的代码。
Func
Func可以看作是一个数据流pipeline。
Var
Var可以看成一个Func中计算时需要的变量,通常用Var表示计算时变化的坐标索引。
Expr
Expr是Var间的一系列操作,比如add = a+b,我觉得表达式的概念像是一个和一些Var绑定的Func,而Func呢算是一个更加通用的概念,可以和不同的输入参数Var进行绑定。
RDom
RDom(reduction domain)在官方教程中居然后来才介绍,可能一开始没有设计这个概念,我觉得RDom算是一个临时的Var,他的任务是用于reduce(也就是遍历后求和等),比如对于某一个维度进行reduce sum,此时用RDom可以方便的定义这个操作。
scheduling方法
example
假设函数如下,默认将第一个元素放置到循环的最内层,也就是说如果是bchw的输入,在构造函数的时候最好应该构造为fuc(w,h,c,b)的形式。
gradient(x, y) = x + y;
for y:
for x:
gradient(...) = ...reorder
调整循环顺序,先计算行方向
gradient.reorder(y, x);
for x:
for y:
gradient_col_major(...) = ...split
把x分为内外循环,虽然实际上不会有什么改变,但是可以为别的优化方法提供基础。
Var x_outer, x_inner;
gradient.split(x, x_outer, x_inner, 2); for y:
for x.v0:
for x.v1 in [0, 1]:
gradient_split(...) = ...fuse
把两层循环合并,与split正好相反
Var fused;
gradient.fuse(x, y, fused);for x.v2:
gradient_fused(...) = ...tiling
通过以上介绍的方式对运算顺序进行组合,我们可以得到一个比较典型的优化策略tiling,就是把整块的运算拆分为多个小块,然后可以通过层面的并行去同步完成,整体的计算。
Var x_outer, x_inner, y_outer, y_inner;
gradient.split(x, x_outer, x_inner, 4);
gradient.split(y, y_outer, y_inner, 4);
gradient.reorder(x_inner, y_inner, x_outer, y_outer);
for y.v5:
for x.v3:
for y.v6 in [0, 3]:
for x.v4 in [0, 3]:
gradient_tiled(...) = ...vectorized
我们可以利用一些单指令多数据并行去同步处理多个数据,此时把数据进行向量化后加载就可以得到相当的大的加速。
Var x_outer, x_inner;
gradient.split(x, x_outer, x_inner, 4);
gradient.vectorize(x_inner);
for y:
for x.v7:
vectorized x.v8 in [0, 3]:
gradient_in_vectors(...) = ...unrolling
循环展开,如果多个像素共享同个数据,这个可以把循环展开避免重复计算。
Var x_outer, x_inner;
gradient.split(x, x_outer, x_inner, 2);
gradient.unroll(x_inner);for y:
for x.v9:
unrolled x.v10 in [0, 1]:
gradient_unroll(...) = ...splitting by factor
如果按比例进行split,会出现一个问题,就是不满足比例的位置被重新计算了,比如7按3分割,那么后面就有两个元素被重复计算了。 
这里是实际执行是会出现问题地方,正确的循环是执行2又1次,但是halide默认执行的是: 外循环 = 0 -> (x_extent + factor - 1)/factor = (1+3-1) / 3 = 0 -> 3 次 内循环 3次
可以看到第三次外循环时对应的值被重复计算了,这个就非常蛋疼了。
Store gradient_split_7x2.0(0, 0) = 0
Store gradient_split_7x2.0(1, 0) = 1
Store gradient_split_7x2.0(2, 0) = 2
Store gradient_split_7x2.0(3, 0) = 3
Store gradient_split_7x2.0(4, 0) = 4
Store gradient_split_7x2.0(5, 0) = 5
Store gradient_split_7x2.0(4, 0) = 4
Store gradient_split_7x2.0(5, 0) = 5
Store gradient_split_7x2.0(6, 0) = 6Fusing + tiling + parallelizing.
融合多个优化策略,首先把图像8x8的图像tiling到2x2个4x4,然后把2x2融合为4,相当于4个4x4,再并行4个线程计算
Var x_outer, y_outer, x_inner, y_inner, tile_index;
gradient.tile(x, y, x_outer, y_outer, x_inner, y_inner, 4, 4);
gradient.fuse(x_outer, y_outer, tile_index);
gradient.parallel(tile_index);
融合多种trick
首先64x64作为tiling
Var x_outer, y_outer, x_inner, y_inner, tile_index;
gradient_fast
.tile(x, y, x_outer, y_outer, x_inner, y_inner, 64, 64)
.fuse(x_outer, y_outer, tile_index)
.parallel(tile_index);然后对每个内部的再tiling到4x2,然后每个x的循环4直接作为向量化计算,y的循环2直接展开。
Var x_inner_outer, y_inner_outer, x_vectors, y_pairs;
gradient_fast
.tile(x_inner, y_inner, x_inner_outer, y_inner_outer, x_vectors, y_pairs, 4, 2)
.vectorize(x_vectors)
.unroll(y_pairs);虽然再tiling到64x64的时候会出现一些重复计算的问题,但是总体来说加速还是很明显的。
Blur 3x3 Example
Blur 3x3是Halide作者给出的经典例子
origin
首先用最原始的方法进行计算,即先遍历一次做x方向的平均,然后再遍历一次做y方向的平均。
{
Buffer<uint8_t> input =
load_image("/home/workspace/Halide/tutorial/images/rgb.png");
Func blur_x("blur_x"), blur_y("blur_y");
blur_x(x, y, c) = cast<uint16_t>(input(x - 1, y, c) + input(x, y, c) +
input(x + 1, y, c)) /
3;
blur_y(x, y, c) = cast<uint8_t>(
(blur_x(x, y - 1, c) + blur_x(x, y, c) + blur_x(x, y + 1, c)) / 3);
blur_x.compute_root();
blur_y.compute_root();
blur_x.print_loop_nest();
printf("-------------\n");
blur_y.print_loop_nest();
Buffer<uint8_t> output(input.width() - 2, input.height() - 2, 3);
output.set_min(1, 1);
blur_y.realize(output);
save_image(output, "blur_1.png");
}通过compute root函数进行AOT编译,对pure func进行实例化,得到输出,可以发现计算对图像遍历了两次。
produce blur_x:
for c:
for y:
for x:
blur_x(...) = ...
consume blur_x:
produce blur_y:
for c:
for y:
for x:
blur_y(...) = ...tile
这里对blur y的进行tile加速,然后把blur x的计算时机挪到blur y进行第内循环的时候。(这里要注意的就是halide的顺序问题,使用变量时最内侧的循环放在最前面,表达计算流程时最后结果也放在前面,也就是作为root,所以compute_at是在计算blur_x的时候调用的)
blur_y.compute_root().tile(x, y, xi, yi, 128, 24);
blur_x.compute_root().compute_at(blur_y, x);得到结果
produce blur_y:
for c:
for y.y:
for x.x:
produce blur_x:
for y:
for x:
blur_x(...) = ...
consume blur_x:
for y.yi in [0, 23]:
for x.xi in [0, 127]:
blur_y(...) = ...parallel
我们还可以继续把tile出来的块并行计算然后内部用向量化来算:
blur_y.compute_root()
.tile(x, y, xi, yi, 128, 24)
.parallel(yi)
.vectorize(xi);
blur_x.compute_root().compute_at(blur_y, x);我感觉halide应该是有一些方法直接绑定两个func到同一个level进行计算的,但是目前还不太清楚怎么弄,通过观察他的运算顺序可以发现我们需要对于每个Func都指定好相同的策略(如果我们想放到同一个looplevel进行计算的话)
produce blur_y:
for c:
for y.y:
for x.x:
produce blur_x:
for y:
for x:
blur_x(...) = ...
consume blur_x:
parallel y.yi in [0, 23]:
vectorized x.xi in [0, 127]:
blur_y(...) = ...parallel 2
详解titling
对于tiling来说,我们传入的xi和yi分别是内部循环中的变量,可以说halide把中间过程的变量表示作为临时变量了。
blur_x.compute_root()
.tile(x, y, xi, yi, 128, 24)得到
produce blur_x:
for c:
for y.y:
for x.x:
for y.yi in [0, 23]:
for x.xi in [0, 127]:
blur_x(...) = ...parallel的位置
上面的y.y和x.x就是被忽略的变量。对于我们有用的就是xi和yi。假设我们要对多个titling的区域进行并行化,那么应该把参数加在这里:
blur_x.compute_root()
.tile(x, y, xi, yi, 128, 24).parallel(yi);produce blur_x:
for c:
for y.y:
for x.x:
parallel y.yi in [0, 23]:
for x.xi in [0, 127]:
blur_x(...) = ...最终结果
这里我们指定blur y计算的loop level为xi,那么可以省去几行代码,但是问题来了,这里的的blur x内部还是在循环y x,不知道生成代码的时候是不是还是重复计算的!这个需要继续去实践才知道。
blur_y.compute_root()
.tile(x, y, xi, yi, 128, 24)
.parallel(yi, 8)
.vectorize(xi, 32);
blur_x.compute_root().compute_at(blur_y, xi);运算顺序输出
produce blur_y:
for c:
for y.y:
for x.x:
parallel y.yi in [0, 23]:
for x.xi.xi in [0, 3]:
produce blur_x:
for y:
for x:
blur_x(...) = ...
consume blur_x:
vectorized x.xi.v0 in [0, 31]:
blur_y(...) = ...definition update
直接定义
有时候我们需要手动指定一些索引按我们需要的方式来更新,或者说直接指定索引计算结果,但是如果在halide中这样做的问题就是他默认会帮你重新循环:
假设我们自定义了两次计算如下:
Func g("g");
g(x, y) = x + y; // Pure definition
g(2, 1) = 42; // First update definition
g(x, 0) = g(x, 1); // Second update definition可以发现每次update的定义会重新生成一次循环,但是明显我们的操作是可以和原来的循环融合的。
produce g:
for y:
for x:
g(...) = ...
g(...) = ...
for x:
g(...) = ...reduction
用RDom进行一些规约也会出现同样的情况
Func f;
f(x, y) = (x + y) / 100.0f;
RDom r(0, 50);
f(x, r) = f(x, r) * f(x, r);可以发现还是重新生成了一次循环,本来RDom的操作应该在x的内部的。
produce f5:
for y:
for x:
f5(...) = ...
for x:
for r19 in [0, 49]:
f5(...) = ...Scheduling update steps
接下来对udpate step进行一些调度,来一个例子:
Func f;
f(x, y) = x * y;
// Set row zero to each row 8
f(x, 0) = f(x, 8);
// Set column zero equal to column 8 plus 2
f(0, y) = f(8, y) + 2;计算流程:
produce f10:
for y:
for x:
f10(...) = ...
for x:
f10(...) = ...
for y:
f10(...) = ...如果需要进行schedule,我们可以对每一个stage进行调整:
f.vectorize(x, 4).parallel(y);则第一个阶段f的计算将会被调整:
produce f10:
parallel y:
for x.x:
vectorized x.v3 in [0, 3]:
f10(...) = ...
for x:
f10(...) = ...
for y:
f10(...) = ...如果需要调整第二个阶段的stage怎么办?可以调用update函数获取某个阶段的句柄,然后进行schedule:
f.update(0).vectorize(x, 4);可以看到第一次update的循环被schedule了
produce f10:
parallel y:
for x.x:
vectorized x.v3 in [0, 3]:
f10(...) = ...
for x.x:
vectorized x.v4 in [0, 3]:
f10(...) = ...
for y:
f10(...) = ...Producer-Consumer Case 0
上面的例子展示了如何对任意阶段的代码进行schedule,但是如何把两个update放到一个循环中呢,halide把这种情况统一为生产者-消费者模型。 比如一个update的写法,如果把它写成两个func,halide就会自动把他们放在同一个循环内部:
Func newf;
newf(x) = x * 2;
newf(x) += 10;
newf(x) = 2 * newf(x);
Func producer, consumer;
producer(x) = x * 2;
producer(x) += 10;
consumer(x) = 2 * producer(x);对比计算顺序就可以看到明显的区别:
produce f15:
for x:
f15(...) = ...
for x:
f15(...) = ...
for x:
f15(...) = ...
produce f14:
for x:
produce f13:
f13(...) = ...
f13(...) = ...
consume f13:
f14(...) = ...Case 1 : 消费者只在pure func阶段消费
接下来继续更加复杂的例子,有Producer-Consumer的同时,Consumer只操作pure func,再对Consumer做update。
producer(x) = x * 17;
consumer(x) = 2 * producer(x);
consumer(x) += 50;
producer.compute_at(consumer, x);在compute_at之前其实halide已经把Producer-Consumer pair放到了一个循环级别内部。经过一次compute_at,把循环重新声明之后,可以看到更加详细的内容。这里还要注意到consumer(x) += 50;这个update操作都是被放到另一次循环了。
produce f21:
for x:
f21(...) = ...
for x:
f21(...) = ...
------------
produce f21:
for x:
produce f20:
f20(...) = ...
consume f20:
f21(...) = ...
for x:
f21(...) = ...Case 2 : 消费者update之后使用生产者的结果
首先执行producer,但是在消费之前先update一次consumer:
producer(x) = x * 17;
consumer(x) = 100 - x * 10;
consumer(x) += producer(x);
producer.compute_at(consumer, x);然后我们producer的运算放到consumer update之后进行运算(这里不用写producer.compute_at(consumer.update(0), x),因为schedule是根据变量来调度的,这里的变量级别即可以确定)。
produce f27:
for x:
f27(...) = ...
for x:
produce f26:
f26(...) = ...
consume f26:
f27(...) = ...Csae 3 : 消费update时多次共享producer
下面生产一次,然后使用两次producer的值
producer(x) = x * 17;
consumer(x) = 170 - producer(x); // update
consumer(x) += producer(x) / 2;
producer.compute_at(consumer, x);这里还是因为update了两次,所以没有把producer给共用。
produce f33:
for x:
produce f32:
f32(...) = ...
consume f32:
f33(...) = ...
for x:
produce f32:
f32(...) = ...
consume f32:
f33(...) = ...compute at
compute at是指当前函数依赖于哪一个变量来计算,比如下面这个例子,当函数依赖于x计算,那么会在最内层的x循环计算4个g到f。如果是依赖于循环y来计算的话,对于x就需要两次循环了。
import halide as hl
f = hl.Func('f')
g = hl.Func('g')
x = hl.Var('x')
y = hl.Var('y')
g[x, y] = x * y
f[x, y] = g[x, y] + g[x, y + 1] + g[x + 1, y] + g[x + 1, y + 1]
g.compute_at(f, x)
f.print_loop_nest()
"""
produce f:
for y:
for x:
produce g:
for y:
for x:
g(...) = ...
consume g:
f(...) = ...
"""
g.compute_at(f, y)
f.print_loop_nest()
"""
produce f:
for y:
produce g:
for y:
for x:
g(...) = ...
consume g:
for x:
f(...) = ...
"""generator代码生成
切记,halide的维度索引是反的,也就是最内层循环放在最前面,和numpy之类的刚好相反。
生成不依赖halidelib的代码
生成代码部分可以去看他的教程,我们可以在生成代码时加上一些参数:
no_runtime, ///< Do not include a copy of the Halide runtime in any generated object file or assembly
no_asserts, ///< Disable all runtime checks, for slightly tighter code.生成c代码和头文件之后,我们一般添加头文件HalideBuffer.H就够了。如果生成的是no_runtime的话,生成的c代码里面是不带runtime的,所以我们需要手动添加头文件HalideRuntime.h。
替换数据类型
生成代码的时候我们只能选择halide内置类型,但是我们实际调用的时候要用自己的类型时候就比较麻烦了,折腾了半天,我才发现可以自定义内置数据,他是构造buffer的时候去检查类型,如果没有对应的类型就直接报错了,但是我们把自己类型注册进去就好了。 下面这个例子就是halide自带的bfloat16类型的组成过程。
template<>
HALIDE_ALWAYS_INLINE halide_type_t halide_type_of<Halide::bfloat16_t>() {
return halide_type_t(halide_type_bfloat, 16);
}生成时选择
halide的一个缺点就是tiling的时候不会自动判断是否能整除(当然也可以选择tiling的策略,但是通过自动补齐、if判断并不适用于所有情况),比如现在要在固定的tile上面计算,所以他的方案是对多个不同的size进行specialize tiling,如果全部都不符合,再fallback到一个通用的处理上。
// 计算出当前的accumulators,然后按倍数进行fallback,也就是4 -> 2 -> 1
const int accumulators = get_accumulator_count(target);
std::vector<std::pair<int, int>> tile_sizes;
const int min_tile_c = 1;
const int max_tile_c = 4;
for (int tile_c = max_tile_c; tile_c >= min_tile_c; tile_c /= 2) {
int tile_x = std::min(8, accumulators / tile_c);
tile_sizes.emplace_back(tile_c, tile_x);
}
tile_sizes.emplace_back(max_tile_c, 1);
Var xo("xo");
Expr output_channels = output_.dim(0).extent();
Expr output_width = output_.dim(1).extent();
for (auto i : tile_sizes) {
const int tile_c = i.first;
const int tile_x = i.second;
output_
.specialize(output_channels % (tile_c * accum_vector_size) == 0 && output_width >= tile_x)
.split(c, co, c, tile_c * accum_vector_size, TailStrategy::RoundUp)
.split(x, xo, x, tile_x, TailStrategy::ShiftInwards)
.reorder(x, c, co, xo, y, b)
.vectorize(c)
.unroll(x);
}tiling的策略
当输入为20,tiling 8的时候,不同的tiling策略的底层做法
- RoundUp
RoundUp就是直接取最小满足的整数倍,直接取到8的整数倍,这也是最直接的方法,当然报错也来的很直接,因为8 * 3 = 24 > 20 sh terminate called after throwing an instance of 'Halide::RuntimeError' what(): Error: Input buffer b0 is accessed at 23, which is beyond the max (19) in dimension 1
- GuardWithIf
自动生成一个special的版本进行fallback sh if ((gemm.extent.1 % 8) != 0) { let t114 = (gemm.extent.0 + 15)/16 let t115 = gemm.extent.1 % 8 let t116 = 0 - (gemm.min.1*gemm.stride.1) let t117 = ((gemm.extent.1/8)*8) + gemm.min.1 . . . }
- ShiftInwards
重新补齐然后按tiling的size进行eval,但是这只能对prue func有效果
- Predicate
这是在内循环中做fallback,和GuardWithIf类似。并且他没有重复eval以及不限制输入尺寸,但也是由于分离增加了代码大小尾tile的处理。