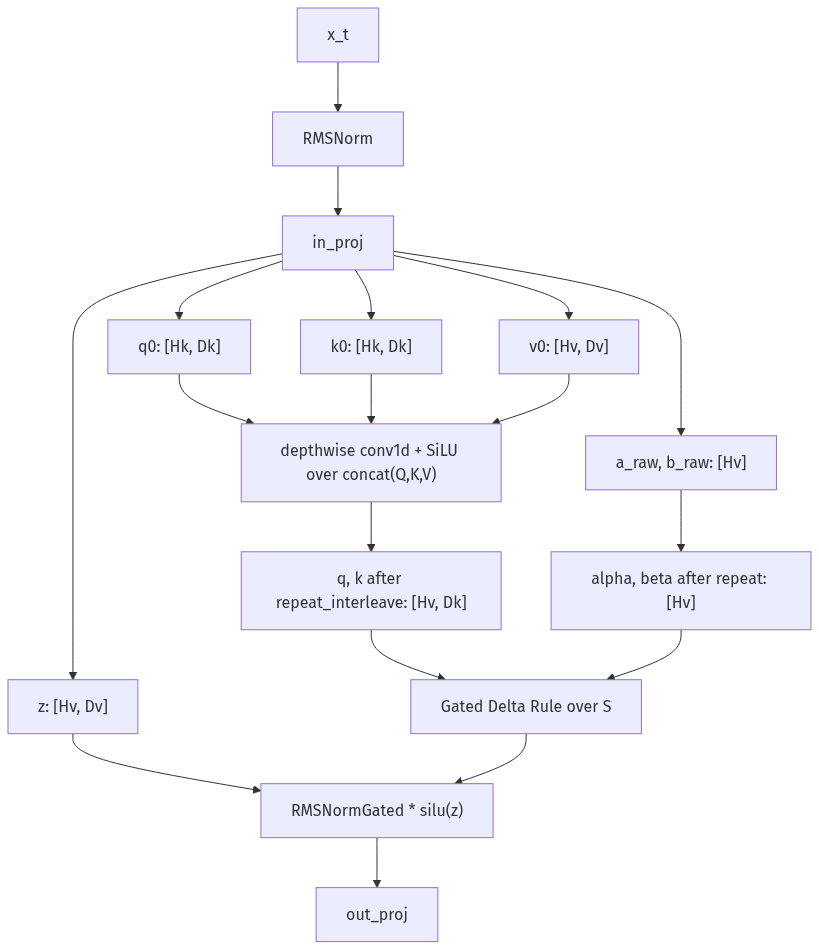
def softplus(x):
return np.log1p(np.exp(x))
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def silu(x):
return x * sigmoid(x)
def rmsnorm_lastdim(x, eps=1e-6):
return x / np.sqrt((x**2).mean(axis=-1, keepdims=True) + eps)
def repeat_interleave_heads(x, repeat):
"""x: [B, S, Hk, D]f32 -> [B, S, Hv, D]f32"""
return np.repeat(x, repeat, axis=2)
def depthwise_conv1d_update(mixed_qkv, conv_state):
"""严格按 HF `torch_causal_conv1d_update` 的逻辑展开。"""
# mixed_qkv: [B, conv_C, 1]f32
# conv_state: [B, conv_C, K_conv]f32
state_len = conv_state.shape[-1]
hidden_states_new = np.concatenate([conv_state, mixed_qkv], axis=-1) # [B, conv_C, K_conv+1]f32
conv_state = hidden_states_new[:, :, -state_len:] # [B, conv_C, K_conv]f32
out = np.empty((B, conv_C, hidden_states_new.shape[-1] - K_conv + 1), dtype=np.float32)
for t in range(out.shape[-1]):
window = hidden_states_new[:, :, t : t + K_conv] # [B, conv_C, K_conv]f32
out[:, :, t] = (window * W_conv[None, :, :]).sum(axis=-1) # [B, conv_C]f32
out = silu(out[:, :, -mixed_qkv.shape[-1]:]) # [B, conv_C, 1]f32
return out, conv_state
def rmsnorm_gated(core_attn_out, z):
# core_attn_out / z: [B, S, Hv, D_v]f32
normed = rmsnorm_lastdim(core_attn_out.astype(np.float32)) # [B, S, Hv, D_v]f32
gated = normed * silu(z.astype(np.float32)) # [B, S, Hv, D_v]f32
return gated * norm_weight[None, None, None, :] # [B, S, Hv, D_v]f32
def gdn_decode_step(hidden_states, S, conv_state):
"""一个和 HF linear_attn decode 数据流对齐的单步 reference."""
# hidden_states: [B, 1, H]f32
hidden_states = hidden_states.astype(np.float32)
hidden_states = rmsnorm_lastdim(hidden_states) # [B, 1, H]f32
# --- L2: four independent projections ---
qkv = hidden_states @ W_qkv # [B, 1, Qd+Kd+Vd]f32
z = (hidden_states @ W_z).reshape(B, 1, Hv, D_v) # [B, 1, Hv, D_v]f32
a = hidden_states @ W_a # [B, 1, Hv]f32
b = hidden_states @ W_b # [B, 1, Hv]f32
# --- L3: causal depthwise conv1d + silu on concatenated QKV ---
mixed_qkv = np.transpose(qkv, (0, 2, 1)) # [B, conv_C, 1]f32
mixed_qkv, conv_state = depthwise_conv1d_update(mixed_qkv, conv_state)
mixed_qkv = np.transpose(mixed_qkv.astype(np.float32), (0, 2, 1)) # [B, 1, conv_C]f32
query, key, value = np.split(mixed_qkv, [Qd, Qd + Kd], axis=-1) # [B,1,Qd], [B,1,Kd], [B,1,Vd]
query = query.reshape(B, 1, Hk, D_k) # [B, 1, Hk, D_k]f32
key = key.reshape(B, 1, Hk, D_k) # [B, 1, Hk, D_k]f32
value = value.reshape(B, 1, Hv, D_v) # [B, 1, Hv, D_v]f32
# --- L3.5: GQA repeat_interleave from Hk to Hv ---
query = repeat_interleave_heads(query, KV_REPEAT) # [B, 1, Hv, D_k]f32
key = repeat_interleave_heads(key, KV_REPEAT) # [B, 1, Hv, D_k]f32
# --- L4: Gated Delta Rule ---
# HF 里直接算 g = -exp(A_log) * softplus(a + dt_bias);这里显式转成 alpha = exp(g)
g = -np.exp(A_log)[None, None, :] * softplus(a + dt_bias[None, None, :]) # [B, 1, Hv]f32
beta = sigmoid(b) # [B, 1, Hv]f32
core_attn_out = np.empty((B, 1, Hv, D_v), dtype=np.float32) # [B, 1, Hv, D_v]f32
for h in range(Hv):
alpha_h = np.exp(g[0, 0, h]).astype(np.float32) # scalar
S_dec = alpha_h * S[0, h] # [D_k, D_v]f32
retrieval = key[0, 0, h] @ S_dec # [D_v]f32
delta = value[0, 0, h] - retrieval # [D_v]f32
S[0, h] = S_dec + beta[0, 0, h] * np.outer(key[0, 0, h], delta) # [D_k, D_v]f32
core_attn_out[0, 0, h] = query[0, 0, h] @ S[0, h] # [D_v]f32
# --- L4n: RMSNormGated ---
out = rmsnorm_gated(core_attn_out, z) # [B, 1, Hv, D_v]f32
# --- L6: out_proj ---
y = out.reshape(B, 1, Vd) @ W_o # [B, 1, H]f32
return y.astype(np.float32), S, conv_state
# 初始化持久化 state
S = np.zeros((B, Hv, D_k, D_v), dtype=np.float32) # [B, Hv, D_k, D_v]f32
conv_state = np.zeros((B, conv_C, K_conv), dtype=np.float32) # [B, conv_C, K_conv]f32
# 跑 3 个 decode step
for t in range(3):
hidden_states = np.random.randn(B, 1, H).astype(np.float32) # [B, 1, H]f32
y, S, conv_state = gdn_decode_step(hidden_states, S, conv_state)
print(f'step {t}: y.shape={y.shape}, conv_state.shape={conv_state.shape}, ||S||_F={np.linalg.norm(S):.3f}')