from numpy.core import *
import matplotlib.pyplot as plt
from scipy.io import loadmat
from numpy import c_, r_
from fucs5 import linearRegCostFunction, trainLinearReg, learningCurve,\
polyFeatures, featureNormalize, plotFit, validationCurve
if __name__ == "__main__":
print('Loading and Visualizing Data ...')
data = loadmat('/media/zqh/程序与工程/Python_study/Machine_learning/\
machine_learning_exam/week5/ex5data1.mat')
X = data['X']
y = data['y']
Xval = data['Xval']
yval = data['yval']
Xtest = data['Xtest']
ytest = data['ytest']
m = size(X, 0)
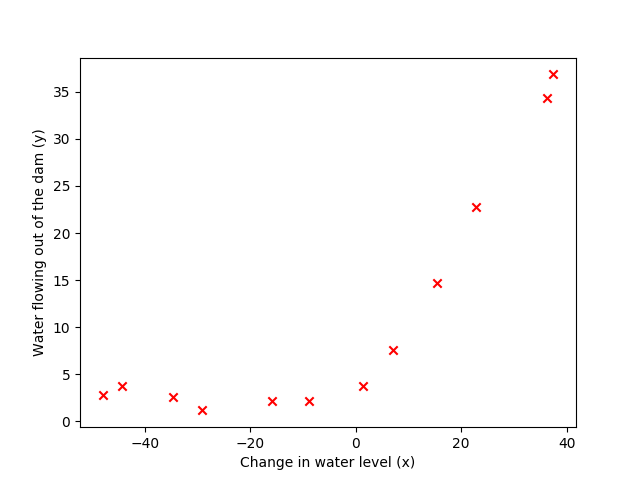
plt.figure()
plt.scatter(X, y, color='r', marker='x')
plt.xlabel('Change in water level (x)')
plt.ylabel('Water flowing out of the dam (y)')
print('Program paused. Press enter to continue.')
theta = array([1, 1]).reshape(-1, 1)
J, _ = linearRegCostFunction(c_[ones((m, 1), float), X], y, theta, 1)
print('Cost at theta = [1 ; 1]: {}\n \
(this value should be about 303.993192)'.format(J))
print('Program paused. Press enter to continue.')
theta = array([1, 1]).reshape(-1, 1)
J, grad = linearRegCostFunction(c_[ones((m, 1), float), X], y, theta, 1)
print('Gradient at theta = [1 ; 1]: [{}; {}] \n\
(this value should be about [-15.303016; 598.250744])'.format(
grad[0], grad[1]))
print('Program paused. Press enter to continue.')
lamda = 0
theta = trainLinearReg(c_[ones((m, 1), float), X], y, lamda)
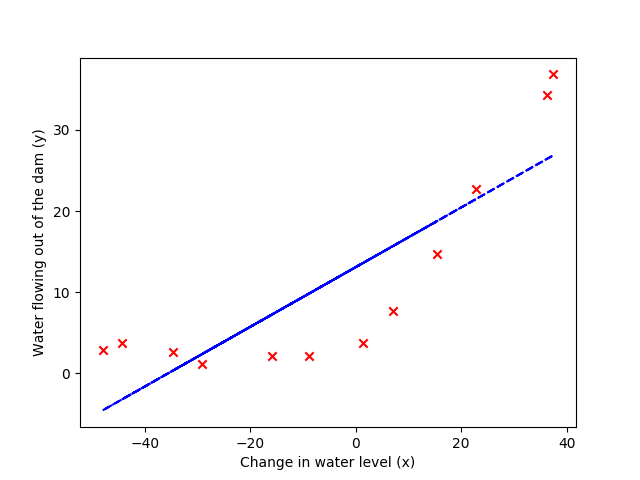
plt.figure()
plt.scatter(X, y, color='r', marker='x')
plt.xlabel('Change in water level (x)')
plt.ylabel('Water flowing out of the dam (y)')
plt.plot(X, c_[ones((m, 1), float), X]@theta, 'b--')
print('Program paused. Press enter to continue.')
lamda = 0
error_train, error_val = \
learningCurve(c_[ones((m, 1), float), X], y,
c_[ones((size(Xval, 0), 1), float), Xval], yval,
lamda)
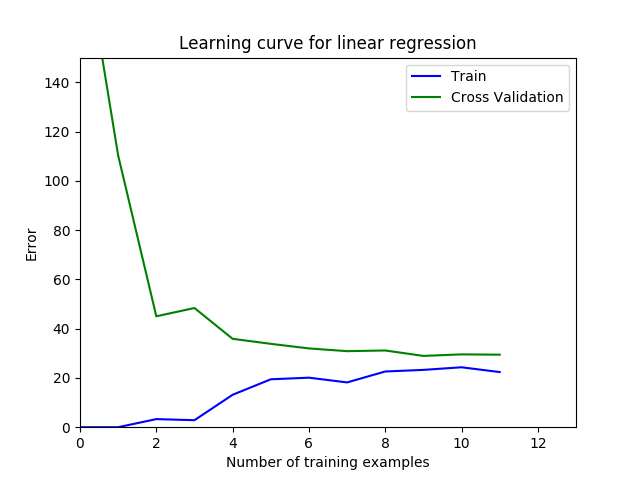
plt.figure()
plt.plot(arange(m), error_train, 'b', arange(m), error_val, 'g')
plt.title('Learning curve for linear regression')
plt.legend(['Train', 'Cross Validation'])
plt.xlabel('Number of training examples')
plt.ylabel('Error')
plt.axis([0, 13, 0, 150])
print('# Training Examples\tTrain Error\tCross Validation Error')
for i in range(m):
print(' \t{}\t\t{:.6f}\t{:.6f}'.format(
i+1, float(error_train[i]), float(error_val[i])))
print('Program paused. Press enter to continue.')
p = 8
X_poly = polyFeatures(X, p)
X_poly, mu, sigma = featureNormalize(X_poly)
X_poly = c_[ones((m, 1), float), X_poly]
X_poly_test = polyFeatures(Xtest, p)
X_poly_test -= mu
X_poly_test /= sigma
X_poly_test = c_[ones((size(X_poly_test, 0), 1), float),
X_poly_test]
X_poly_val = polyFeatures(Xval, p)
X_poly_val -= mu
X_poly_val /= sigma
X_poly_val = c_[ones((size(X_poly_val, 0), 1), float),
X_poly_val]
print('Normalized Training Example 1:')
print(' {} '.format(X_poly[0, :]))
print('Program paused. Press enter to continue.')
lamda = 0
theta = trainLinearReg(X_poly, y, lamda)
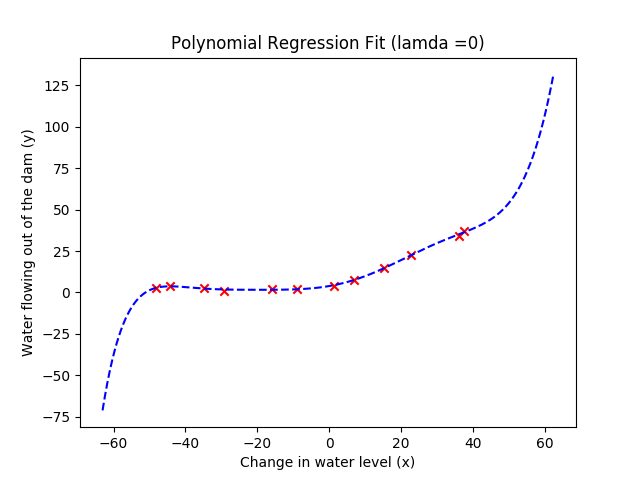
plt.figure()
plt.scatter(X, y, c='r', marker='x')
plotFit(min(X), max(X), mu, sigma, theta, p)
plt.xlabel('Change in water level (x)')
plt.ylabel('Water flowing out of the dam (y)')
plt.title('Polynomial Regression Fit (lamda ={})'.format(lamda))
plt.figure()
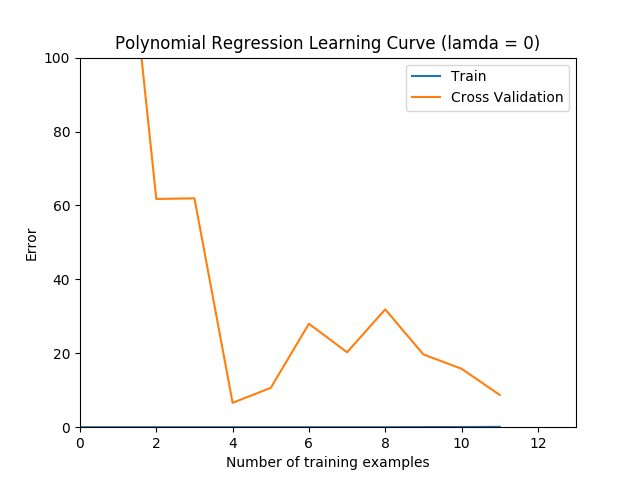
error_train, error_val = learningCurve(
X_poly, y, X_poly_val, yval, lamda)
plt.plot(arange(m), error_train, arange(m), error_val)
plt.title('Polynomial Regression Learning Curve (lamda = {})'
.format(lamda))
plt.xlabel('Number of training examples')
plt.ylabel('Error')
plt.axis([0, 13, 0, 100])
plt.legend(['Train', 'Cross Validation'])
print('Polynomial Regression (lamda = {})'.format(lamda))
print('# Training Examples\tTrain Error\tCross Validation Error')
for i in range(m):
print(' \t{}\t\t{:.6f}\t{:.6f}'.format(
i+1, float(error_train[i]), float(error_val[i])))
print('Program paused. Press enter to continue.')
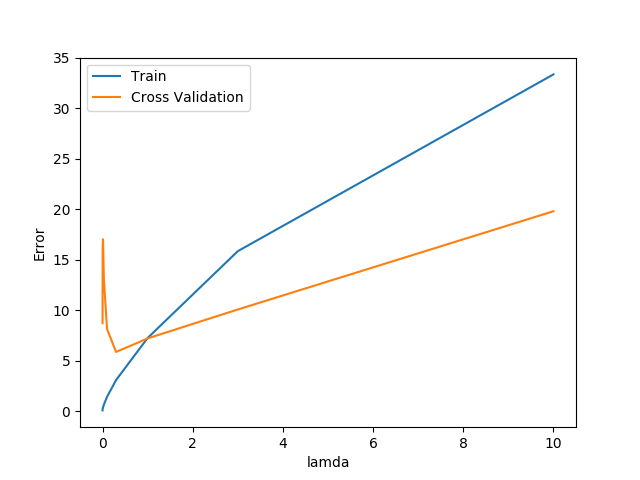
lamda_vec, error_train, error_val = validationCurve(
X_poly, y, X_poly_val, yval)
plt.figure()
plt.plot(lamda_vec, error_train, lamda_vec, error_val)
plt.legend(['Train', 'Cross Validation'])
plt.xlabel('lamda')
plt.ylabel('Error')
print('lamda\t\tTrain Error\tValidation Error')
for i in range(size(lamda_vec)):
print(' {:.6f}\t{:.6f}\t{:.6f}'.format(float(lamda_vec[i]),
float(error_train[i]),
float(error_val[i])))
print('Program paused. Press enter to continue.')
plt.show()
|