from numpy.core import *
from numpy.random import *
from numpy import c_, r_
import matplotlib.pyplot as plt
from scipy.io import loadmat
from scipy.optimize import fmin_cg
from fucs4 import randInitializeWeights, costFuc, gradFuc, predict
if __name__ == "__main__":
print('generate Data ...')
tarin_nums = 5000
test_nums = 100
train_x = rand(tarin_nums, 1)*9+1
train_y = exp(-train_x)
test_x = rand(test_nums, 1)*9+1
test_y = exp(-test_x)
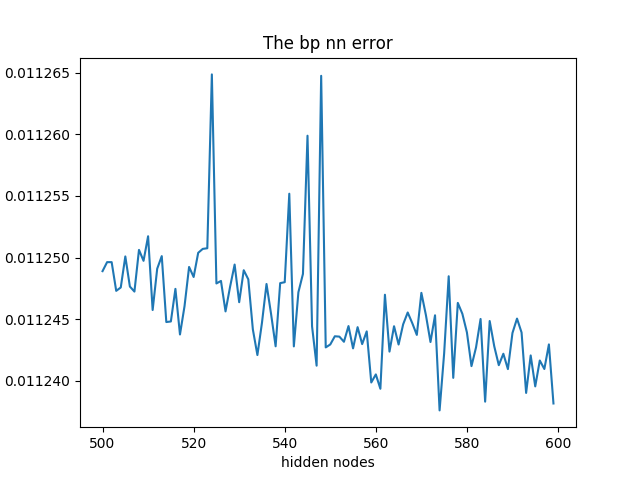
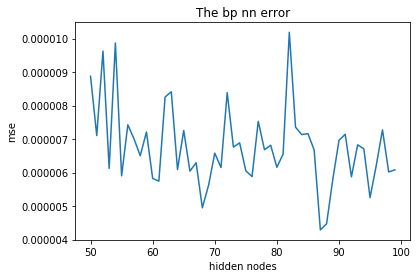
mse = zeros(50)
for i in range(50):
print('training times:{}'.format(i))
input_layer_size = 1
hidden_layer_size = 50+i
num_labels = 1
initial_Theta1 = randInitializeWeights(
input_layer_size, hidden_layer_size)
initial_Theta2 = randInitializeWeights(
hidden_layer_size, num_labels)
initial_nn_params = r_[
initial_Theta1.reshape(-1, 1), initial_Theta2.reshape(-1, 1)]
MaxIter = 50
lamda = 1
nn_params = fmin_cg(costFuc, initial_nn_params.flatten(), gradFuc,
(input_layer_size, hidden_layer_size,
num_labels, train_x, train_y, lamda),
maxiter=MaxIter)
Theta1 = nn_params[: hidden_layer_size * (input_layer_size + 1)] \
.reshape(hidden_layer_size, input_layer_size + 1)
Theta2 = nn_params[hidden_layer_size * (input_layer_size + 1):] \
.reshape(num_labels, hidden_layer_size + 1)
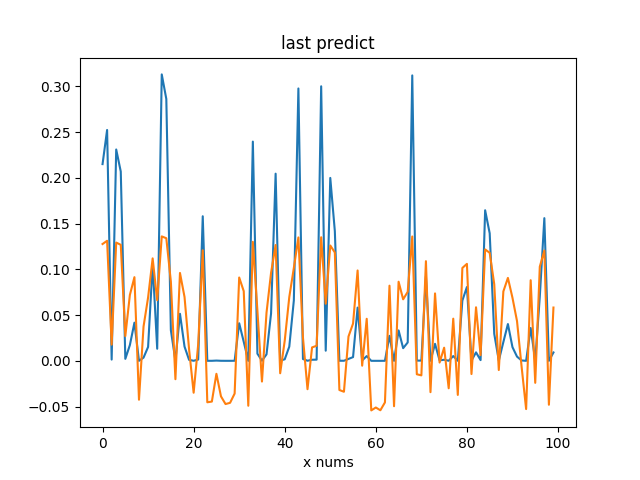
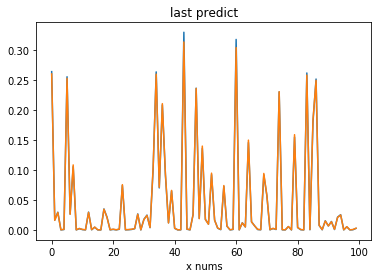
pred = predict(Theta1, Theta2, test_x)
mse[i] = mean((pred-test_y)**2)
plt.figure()
plt.title('The bp nn error')
plt.plot(range(50, 50+50), mse)
plt.xlabel('hidden nodes')
plt.ylabel('mse')
plt.figure()
plt.title('last predict')
plt.xlabel('x nums')
plt.plot(range(100), test_y, range(100), pred)
plt.show()
|