from numpy.core import *
from numpy.matrixlib import mat
from numpy import c_, r_, meshgrid, square, where, min, max
from scipy.special import expit
from scipy.optimize import fmin_cg
import matplotlib.pyplot as plt
from sklearn import svm
from re import sub, split
from nltk.stem import PorterStemmer
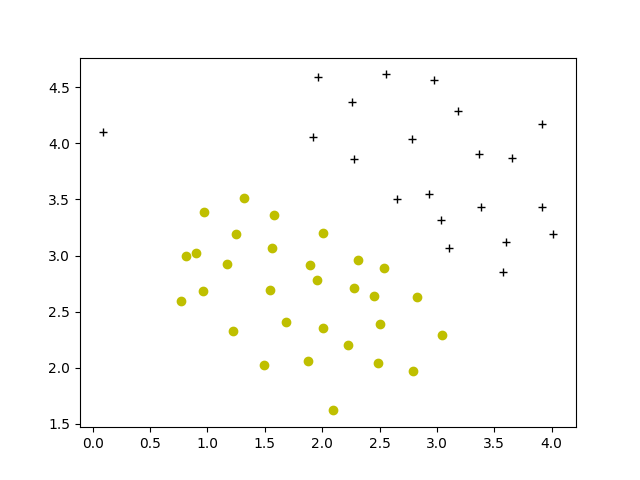
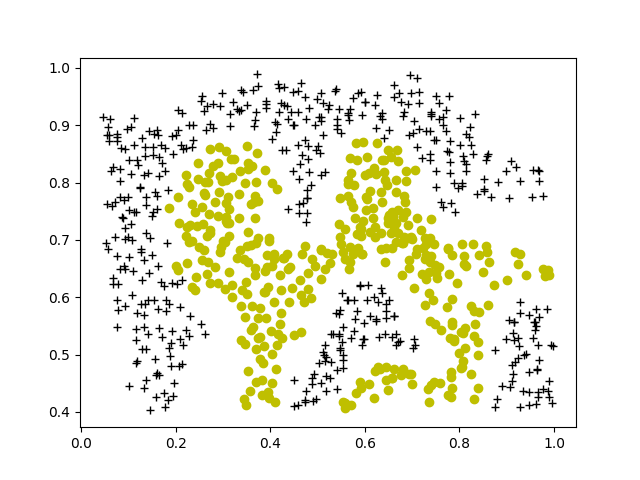
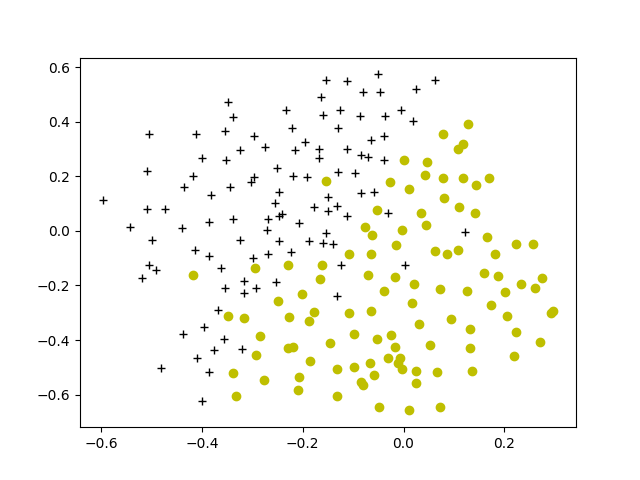
def plotData(X: ndarray, y: ndarray):
pos = nonzero(y == 1)
neg = nonzero(y == 0)
plt.figure()
plt.plot(X[pos[0], 0], X[pos[0], 1], 'k+')
plt.plot(X[neg[0], 0], X[neg[0], 1], 'yo')
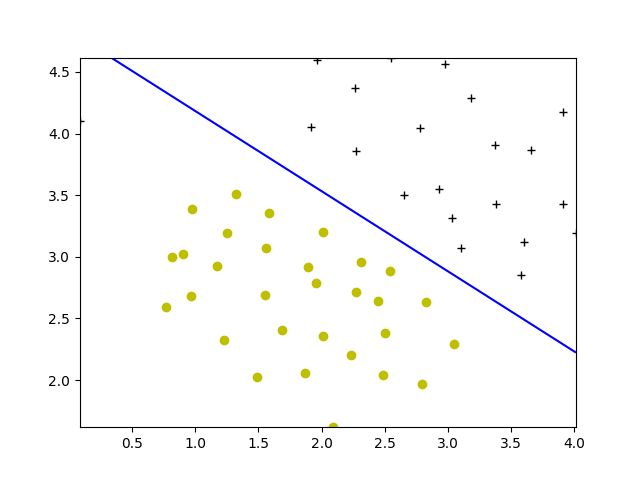
def visualizeBoundaryLinear(X, y, model):
xp = linspace(min(X[:, 0]), max(X[:, 0]), 100)
yp = linspace(min(X[:, 1]), max(X[:, 1]), 100)
plotData(X, y)
YY, XX = meshgrid(yp, xp)
xy = vstack([XX.ravel(), YY.ravel()]).T
Z = model.decision_function(xy).reshape(XX.shape)
plt.contour(XX, YY, Z, colors='b', levels=0)
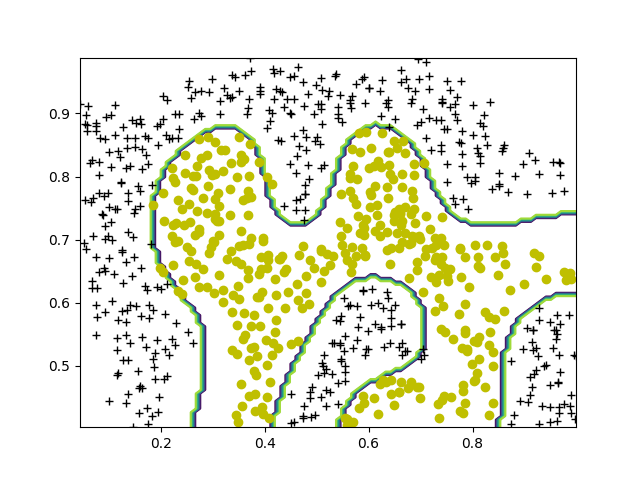
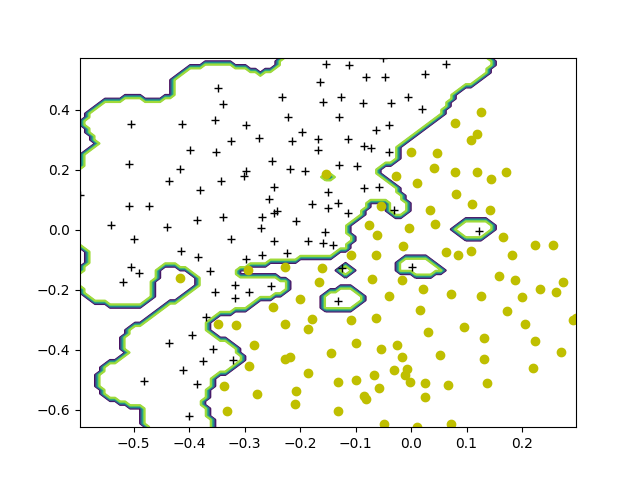
def visualizeBoundary(X: ndarray, y: ndarray, model: svm.SVC, varargin=0):
plotData(X, y)
x1plot = linspace(min(X[:, 0]), max(X[:, 0]), 100)
x2plot = linspace(min(X[:, 1]), max(X[:, 1]), 100)
xx, yy = meshgrid(x1plot, x2plot)
Z = model.predict(c_[xx.ravel(), yy.ravel()])
Z.resize(xx.shape)
plt.contour(xx, yy, Z)
def gaussianKernel(x1: ndarray, x2: ndarray, sigma):
m = size(x1, 0)
n = size(x2, 0)
sim = 0
M = x1@x2.T
H1 = sum(square(mat(x1)), 1)
H2 = sum(square(mat(x2)), 1)
D = H1+H2.T-2*M
sim = exp(-D/(2*sigma*sigma))
return sim
def dataset3Params(X: ndarray, y: ndarray, Xval: ndarray, yval: ndarray):
C = 1
sigma = 0.3
C_vec = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]
sigma_vec = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]
error_val = zeros((len(C_vec), len(sigma_vec)))
for i in range(len(C_vec)):
for j in range(len(sigma_vec)):
def mykernel(x1, x2): return gaussianKernel(x1, x2, sigma_vec[j])
model = svm.SVC(C=C_vec[i], kernel=mykernel)
model.fit(X, y.ravel())
pred = model.predict(Xval)
error_val[i, j] = mean(array(pred != yval))
i, j = where(error_val == min(error_val))
C = C_vec[i[0]]
sigma = sigma_vec[j[0]]
return C, sigma
def readFile(filename: str):
with open(filename) as fid:
file_contents = fid.read()
return file_contents
def getVocabList():
fid = open('vocab.txt')
n = 1899
vocabList = dict()
for i in range(n):
line = fid.readline()
ll = line.strip().split('\t')
vocabList[i] = ll[1]
fid.close()
return vocabList
def processEmail(email_contents: str):
vocabList = getVocabList()
word_indices = []
email_contents = email_contents.lower()
email_contents = sub('<[^<>]+>', ' ', email_contents)
email_contents = sub('[0-9]+', 'number', email_contents)
email_contents = sub('(http|https)://[^\s]*', 'httpaddr', email_contents)
email_contents = sub('[^\s]+@[^\s]+', 'emailaddr', email_contents)
email_contents = sub('[$]+', 'dollar', email_contents)
print('\n==== Processed Email ====')
l = 0
s = split(
r',|\.|/|;|\'|`|\[|\]|<|>|\?|:|"|\{|\}|\~|!|@|#|\$|#|\^|&|\(|\)|-|=|\_|\+|\
,|。|、|;|‘|’|【|】|·|!| |…|(|)', email_contents)
s = [it for it in s if it.isalnum()]
stemmer = PorterStemmer()
for i in range(len(s)):
st = stemmer.stem(s[i])
for i in range(len(vocabList)):
if vocabList[i] == st:
word_indices.append(i+1)
if (l + len(st) + 1) > 78:
l = 0
print('{}'.format(st), end=' ')
l = l + len(st) + 1
print('\n\n=======================')
return word_indices
def emailFeatures(word_indices: list)->ndarray:
n = 1899
x = zeros((n, 1))
for i in word_indices:
x[i-1] = 1
return x
|