import matplotlib.pyplot as plt
from numpy import diag, linspace, meshgrid, c_, r_, isinf
from numpy.random import rand, randn
from numpy.core import *
from numpy.linalg import det, pinv, norm
from numpy.matrixlib import mat
def estimateGaussian(X: ndarray):
m, n = shape(X)
mu = zeros((n, 0))
sigma2 = zeros((n, 0))
mu = mean(X, 0)
sigma2 = 1/m * sum((X-mu.reshape(1, -1))**2, 0)
return mu, sigma2
def multivariateGaussian(X: ndarray, mu: ndarray, Sigma2: ndarray):
k = len(mu)
if (size(mat(Sigma2), 1) == 1) or (size(mat(Sigma2), 0) == 1):
Sigma2 = diag(Sigma2)
x = X - mu.reshape(1, -1)
p = (2 * pi)**(- k / 2) * det(Sigma2) ** (-0.5) * \
exp(-0.5 * sum(x@pinv(Sigma2)*x, 1))
return p
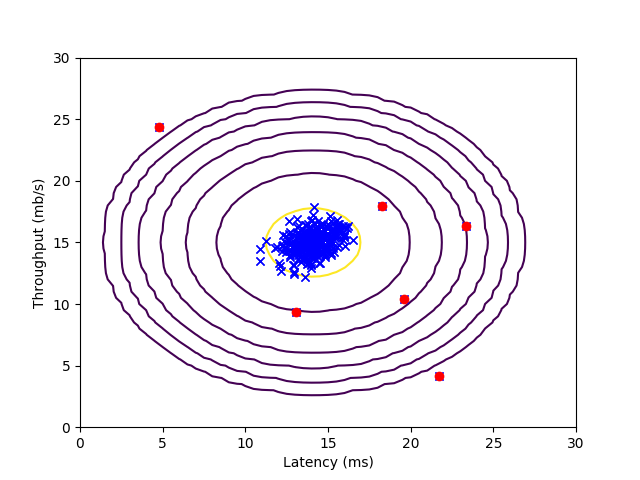
def visualizeFit(X, mu, sigma2):
X1, X2 = meshgrid(arange(0, 35.5, .5), arange(0, 35.5, .5))
Z = multivariateGaussian(c_[X1.ravel(), X2.ravel()], mu, sigma2)
Z = reshape(Z, shape(X1))
plt.plot(X[:, 0], X[:, 1], 'bx')
if (sum(isinf(Z)) == 0):
plt.contour(X1, X2, Z, list(map(lambda x: 10**x, range(-20, 0, 3))))
def selectThreshold(yval: ndarray, pval: ndarray):
bestEpsilon = 0
bestF1 = 0
F1 = 0
stepsize = (max(pval) - min(pval)) / 1000
for epsilon in arange(min(pval), max(pval), stepsize):
predictions = (pval < epsilon)
fp = sum((predictions == 1) & (yval.ravel() == 0))
fn = sum((predictions == 0) & (yval.ravel() == 1))
tp = sum((predictions == 1) & (yval.ravel() == 1))
prec = tp / (tp + fp)
rec = tp / (tp + fn)
F1 = 2 * prec * rec / (prec + rec)
if F1 > bestF1:
bestF1 = F1
bestEpsilon = epsilon
return bestEpsilon, bestF1
def cofiCostFunc(params, Y, R, num_users, num_movies, num_features, lamda):
X = reshape(params[: num_movies*num_features],
(num_movies, num_features))
Theta = reshape(params[num_movies*num_features:],
(num_users, num_features))
J = 0
X_grad = zeros(shape(X))
Theta_grad = zeros(shape(Theta))
J_temp = (X @ Theta.T - Y) ** 2
J = sum(J_temp[nonzero(R == 1)])/2 + lamda/2 * \
sum(Theta ** 2) + lamda/2 * sum(X ** 2)
X_grad = ((X@Theta.T - Y) * R) @ Theta + lamda*X
Theta_grad = ((X@Theta.T - Y) * R).T @ X + lamda*Theta
grad = r_[X_grad.ravel(), Theta_grad.ravel()]
return J, grad
def computeNumericalGradient(J, theta: ndarray):
numgrad = zeros(shape(theta))
perturb = zeros(shape(theta))
e = 1e-4
for p in range(size(theta)):
perturb[p] = e
loss1 = J(theta - perturb)[0]
loss2 = J(theta + perturb)[0]
numgrad[p] = (loss2 - loss1) / (2*e)
perturb[p] = 0
return numgrad
def checkCostFunction(lamda=0):
X_t = rand(4, 3)
Theta_t = rand(5, 3)
Y = X_t @ Theta_t.T
Y[nonzero(rand(size(Y, 0), size(Y, 1)) > 0.5)] = 0
R = zeros(shape(Y))
R[nonzero(Y != 0)] = 1
X = randn(size(X_t))
Theta = randn(size(Theta_t))
num_users = size(Y, 1)
num_movies = size(Y, 0)
num_features = size(Theta_t, 1)
def Costfunc(x): return cofiCostFunc(
x, Y, R, num_users, num_movies, num_features, lamda)
numgrad = computeNumericalGradient(Costfunc, r_[X.ravel(), Theta.ravel()])
cost, grad = cofiCostFunc(r_[X.ravel(), Theta.ravel()], Y, R, num_users, num_movies,
num_features, lamda)
print(numgrad, grad)
print('The above two columns you get should be very similar.\n\
(Left-Your Numerical Gradient, Right-Analytical Gradient)\n')
diff = norm(numgrad-grad)/norm(numgrad+grad)
print('If your cost function implementation is correct, then \n\
the relative difference will be small (less than 1e-9). \n\
\nRelative Difference: {}\n'.format(diff))
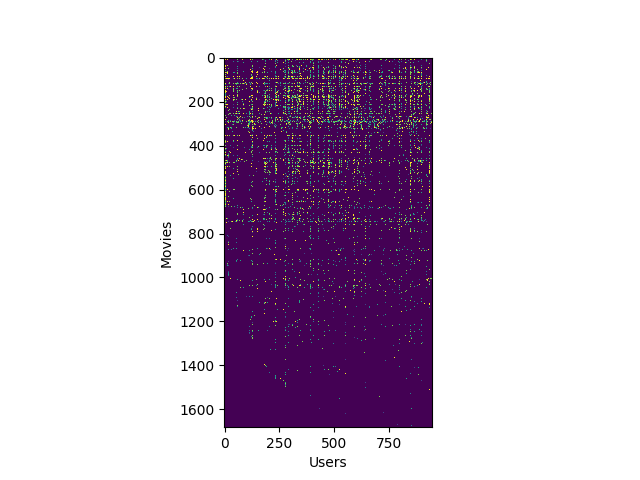
def loadMovieList():
n = 1682
movieList = []
with open('movie_ids.txt') as fid:
for line in fid:
movieList.append(line.strip().split(' ', maxsplit=1)[1])
return movieList
def normalizeRatings(Y: ndarray, R: ndarray):
m, n = shape(Y)
Ymean = zeros((m, 1))
Ynorm = zeros(shape(Y))
for i in range(m):
idx = nonzero(R[i, :] == 1)
Ymean[i, :] = mean(Y[i, idx])
Ynorm[i, idx] = Y[i, idx] - Ymean[i]
return Ynorm, Ymean
|