#@title Imports and Global Variables (run this cell first) { display-mode: "form" } """ The book uses a custom matplotlibrc file, which provides the unique styles for matplotlib plots. If executing this book, and you wish to use the book's styling, provided are two options: 1. Overwrite your own matplotlibrc file with the rc-file provided in the book's styles/ dir. See http://matplotlib.org/users/customizing.html 2. Also in the styles is bmh_matplotlibrc.json file. This can be used to update the styles in only this notebook. Try running the following code: import json s = json.load(open("../styles/bmh_matplotlibrc.json")) matplotlib.rcParams.update(s) """ from __future__ import absolute_import, division, print_function #@markdown This sets the warning status (default is `ignore`, since this notebook runs correctly) warning_status = "ignore"#@param ["ignore", "always", "module", "once", "default", "error"] import warnings warnings.filterwarnings(warning_status) with warnings.catch_warnings(): warnings.filterwarnings(warning_status, category=DeprecationWarning) warnings.filterwarnings(warning_status, category=UserWarning)
import numpy as np import os #@markdown This sets the styles of the plotting (default is styled like plots from [FiveThirtyeight.com](https://fivethirtyeight.com/) matplotlib_style = 'fivethirtyeight'#@param ['fivethirtyeight', 'bmh', 'ggplot', 'seaborn', 'default', 'Solarize_Light2', 'classic', 'dark_background', 'seaborn-colorblind', 'seaborn-notebook'] import matplotlib.pyplot as plt; plt.style.use(matplotlib_style) import matplotlib.axes as axes; from matplotlib.patches import Ellipse %matplotlib inline import seaborn as sns; sns.set_context('notebook') from IPython.core.pylabtools import figsize #@markdown This sets the resolution of the plot outputs (`retina` is the highest resolution) notebook_screen_res = 'retina'#@param ['retina', 'png', 'jpeg', 'svg', 'pdf'] %config InlineBackend.figure_format = notebook_screen_res
import tensorflow as tf tfe = tf.contrib.eager
# Eager Execution #@markdown Check the box below if you want to use [Eager Execution](https://www.tensorflow.org/guide/eager) #@markdown Eager execution provides An intuitive interface, Easier debugging, and a control flow comparable to Numpy. You can read more about it on the [Google AI Blog](https://ai.googleblog.com/2017/10/eager-execution-imperative-define-by.html) use_tf_eager = False#@param {type:"boolean"}
# Use try/except so we can easily re-execute the whole notebook. if use_tf_eager: try: tf.enable_eager_execution() except: pass
import tensorflow_probability as tfp tfd = tfp.distributions tfb = tfp.bijectors
defevaluate(tensors): """Evaluates Tensor or EagerTensor to Numpy `ndarray`s. Args: tensors: Object of `Tensor` or EagerTensor`s; can be `list`, `tuple`, `namedtuple` or combinations thereof. Returns: ndarrays: Object with same structure as `tensors` except with `Tensor` or `EagerTensor`s replaced by Numpy `ndarray`s. """ if tf.executing_eagerly(): return tf.contrib.framework.nest.pack_sequence_as( tensors, [t.numpy() if tf.contrib.framework.is_tensor(t) else t for t in tf.contrib.framework.nest.flatten(tensors)]) return sess.run(tensors)
class_TFColor(object): """Enum of colors used in TF docs.""" red = '#F15854' blue = '#5DA5DA' orange = '#FAA43A' green = '#60BD68' pink = '#F17CB0' brown = '#B2912F' purple = '#B276B2' yellow = '#DECF3F' gray = '#4D4D4D' def__getitem__(self, i): return [ self.red, self.orange, self.green, self.blue, self.pink, self.brown, self.purple, self.yellow, self.gray, ][i % 9] TFColor = _TFColor()
defsession_options(enable_gpu_ram_resizing=True, enable_xla=True): """ Allowing the notebook to make use of GPUs if they're available. XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that optimizes TensorFlow computations. """ config = tf.ConfigProto() config.log_device_placement = True if enable_gpu_ram_resizing: # `allow_growth=True` makes it possible to connect multiple colabs to your # GPU. Otherwise the colab malloc's all GPU ram. config.gpu_options.allow_growth = True if enable_xla: # Enable on XLA. https://www.tensorflow.org/performance/xla/. config.graph_options.optimizer_options.global_jit_level = ( tf.OptimizerOptions.ON_1) return config
defreset_sess(config=None): """ Convenience function to create the TF graph & session or reset them. """ if config isNone: config = session_options() global sess tf.reset_default_graph() try: sess.close() except: pass sess = tf.InteractiveSession(config=config)
reset_sess()
WARNING: Logging before flag parsing goes to stderr.
W0726 19:11:25.497503 140237485999936 lazy_loader.py:50]
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
A little
more on TensorFlow and TensorFlow Probability
从根本上说,TensorFlow使用图形进行计算,其中图形表示计算作为各个操作之间的依赖关系。在Tensorflow图的编程范例中,我们首先定义数据流图,然后创建TensorFlow会话以运行图的部分。
Tensorflow
tf.Session()对象运行图形以获取我们想要建模的变量。在下面的示例中,我们使用了一个全局会话对象sess,我们在上面的“Imports
and Global Variables”部分中创建了它。
if tf.executing_eagerly(): data_generator_ = tf.contrib.framework.nest.pack_sequence_as(data_generator,[t.numpy() if tf.contrib.framework.is_tensor(t) else t for t in tf.contrib.framework.nest.flatten(data_generator)]) else: data_generator_ = sess.run(data_generator) print("Value of sample from data generator random variable:", data_generator_)
Value of sample from data generator random variable: 1.0
AttributeError: Tensor.graph is meaningless when eager execution is enabled.
As mentioned in the previous chapter, we have a nifty tool that
allows us to create code that's usable in both graph mode and eager
mode. The custom evaluate() function allows us to evaluate
tensors whether we are operating in TF graph or eager mode. A
generalization of our data generator example above, the function looks
like the following:
defevaluate(tensors): if tf.executing_eagerly(): return tf.contrib.framework.nest.pack_sequence_as( tensors, [t.numpy() if tf.contrib.framework.is_tensor(t) else t for t in tf.contrib.framework.nest.flatten(tensors)]) with tf.Session() as sess: return sess.run(tensors)
Each of the tensors corresponds to a NumPy-like output. To
distinguish the tensors from their NumPy-like counterparts, we will use
the convention of appending an underscore to the version of the tensor
that one can use NumPy-like arrays on. In other words, the output of
evaluate() gets named as variable +
_ = variable_ . Now, we can do our Poisson
sampling using both the evaluate() function and this new
convention for naming Python variables in TFP.
print("Sample from exponential distribution before evaluation: ", parameter) print("Evaluated sample from exponential distribution: ", parameter_)
Sample from exponential distribution before evaluation: Tensor("poisson_param_1/sample/Reshape:0", shape=(), dtype=float32)
Evaluated sample from exponential distribution: 0.34844726
# Show results print("two predetermined data points: ", data_) print("\n mean of our data: ", np.mean(data_)) print("\n random sample from poisson distribution \n with the mean as the poisson's rate: \n", poisson_)
two predetermined data points: [10. 5.]
mean of our data: 7.5
random sample from poisson distribution
with the mean as the poisson's rate:
1.0
W0726 19:11:30.352059 140237485999936 deprecation.py:323] From <ipython-input-19-e4e347c50353>:6: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.cast` instead.
W0726 19:11:30.359435 140237485999936 deprecation.py:323] From <ipython-input-19-e4e347c50353>:26: make_simple_step_size_update_policy (from tensorflow_probability.python.mcmc.hmc) is deprecated and will be removed after 2019-05-22.
Instructions for updating:
Use tfp.mcmc.SimpleStepSizeAdaptation instead.
W0726 19:11:30.363615 140237485999936 deprecation.py:506] From <ipython-input-19-e4e347c50353>:27: calling HamiltonianMonteCarlo.__init__ (from tensorflow_probability.python.mcmc.hmc) with step_size_update_fn is deprecated and will be removed after 2019-05-22.
Instructions for updating:
The `step_size_update_fn` argument is deprecated. Use `tfp.mcmc.SimpleStepSizeAdaptation` instead.
W0726 19:11:30.403772 140237485999936 deprecation.py:323] From /home/zqh/miniconda3/lib/python3.7/site-packages/tensorflow_probability/python/distributions/uniform.py:182: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
# 由于HMC在无约束空间上运行,我们需要对样本进行变换,使它们存在于真实空间中。 unconstraining_bijectors = [ tfp.bijectors.Identity(), # Maps R to R. tfp.bijectors.Identity() # Maps R to R. ]
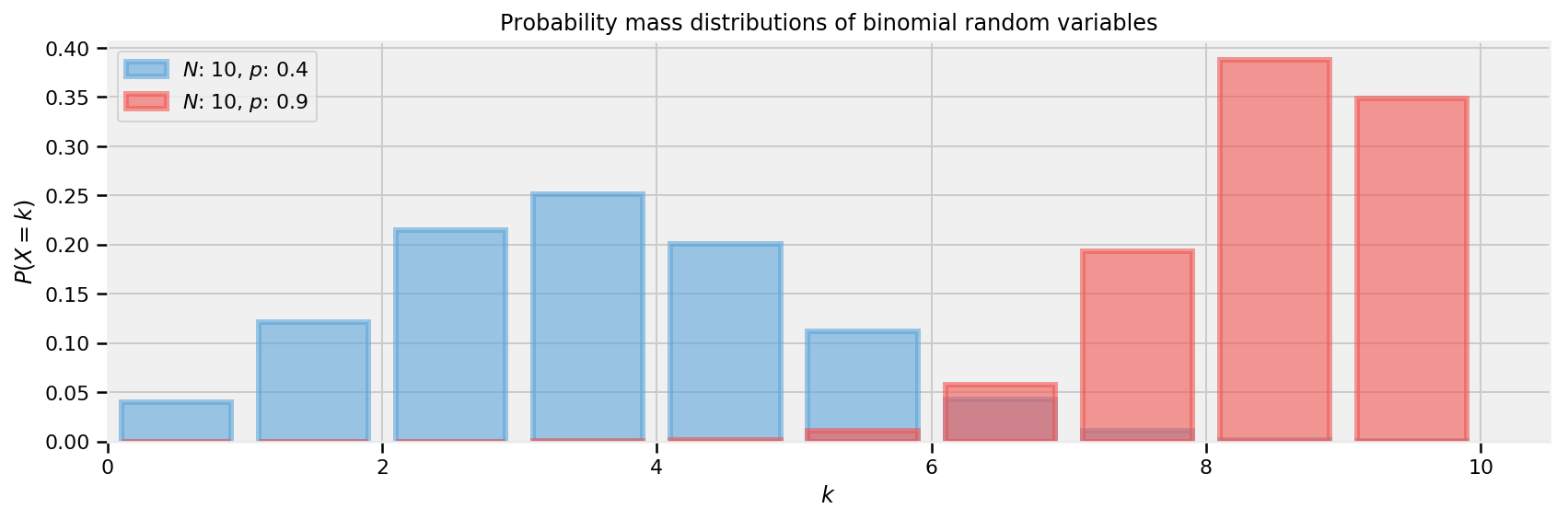
plt.legend(loc="upper left") plt.xlim(0, 10.5) plt.xlabel("$k$") plt.ylabel("$P(X = k)$") plt.title("Probability mass distributions of binomial random variables")
defalt_joint_log_prob(yes_responses, N, prob_cheating): """ Alternative joint log probability optimization function. Args: yes_responses: Integer for total number of affirmative responses N: Integer for number of total observation prob_cheating: Test probability of a student actually cheating Returns: Joint log probability optimization function. """ tfd = tfp.distributions rv_prob = tfd.Uniform(name="rv_prob", low=0., high=1.) p_skewed = 0.5 * prob_cheating + 0.25 rv_yes_responses = tfd.Binomial(name="rv_yes_responses", total_count=tf.to_float(N), probs=p_skewed)
# Set the chain's start state. initial_chain_state = [ 0.2 * tf.ones([], dtype=tf.float32, name="init_skewed_p") ]
# Since HMC operates over unconstrained space, we need to transform the # samples so they live in real-space. unconstraining_bijectors = [ tfp.bijectors.Sigmoid(), # Maps [0,1] to R. ]
# Define a closure over our joint_log_prob. # unnormalized_posterior_log_prob = lambda *args: alt_joint_log_prob(headsflips, total_yes, N, *args) unnormalized_posterior_log_prob = lambda *args: alt_joint_log_prob(total_yes, N, *args)
# Initialize the step_size. (It will be automatically adapted.) with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE): step_size = tf.get_variable( name='skewed_step_size', initializer=tf.constant(0.5, dtype=tf.float32), trainable=False, use_resource=True )
# Sample from the chain. [ posterior_skewed_p ], kernel_results = tfp.mcmc.sample_chain( num_results=number_of_steps, num_burnin_steps=burnin, current_state=initial_chain_state, kernel=hmc)
# Initialize any created variables. # This prevents a FailedPreconditionError init_g = tf.global_variables_initializer() init_l = tf.local_variables_initializer()
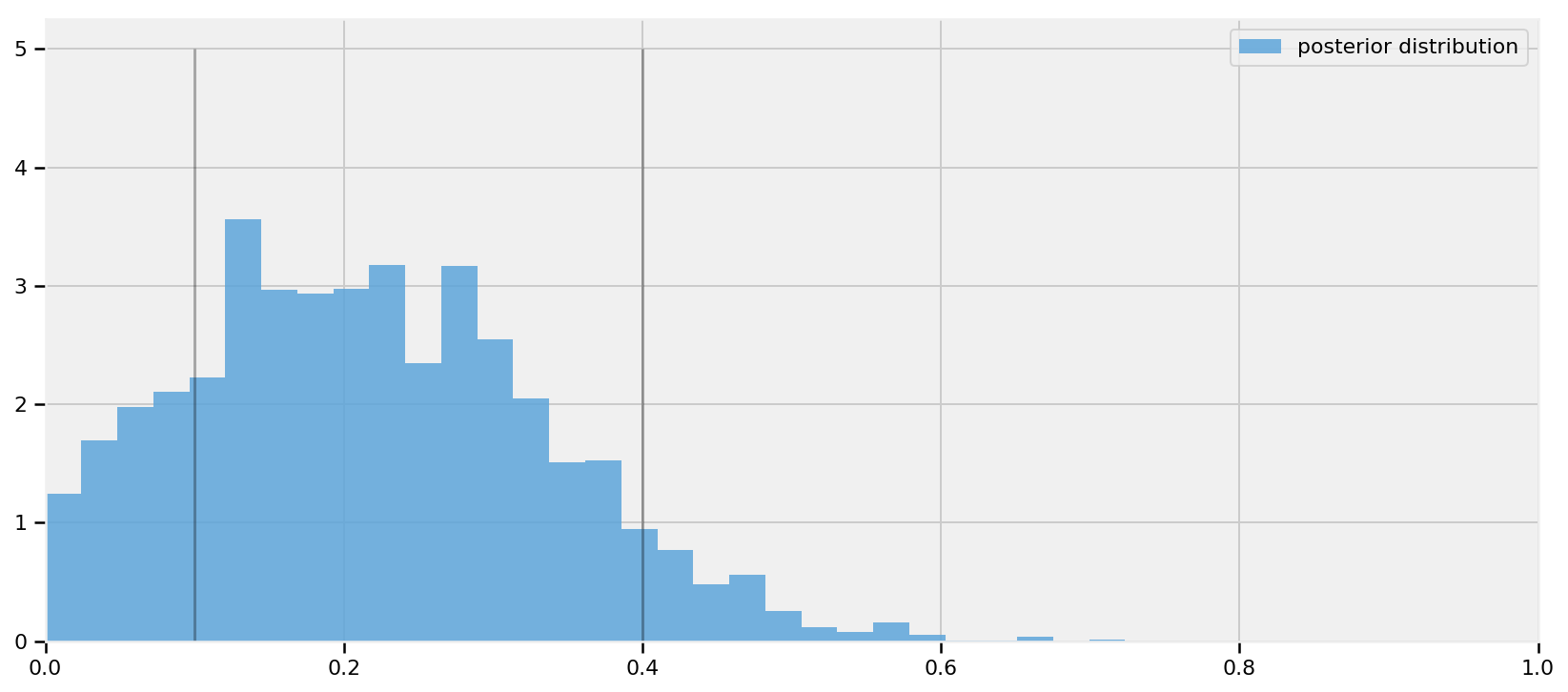
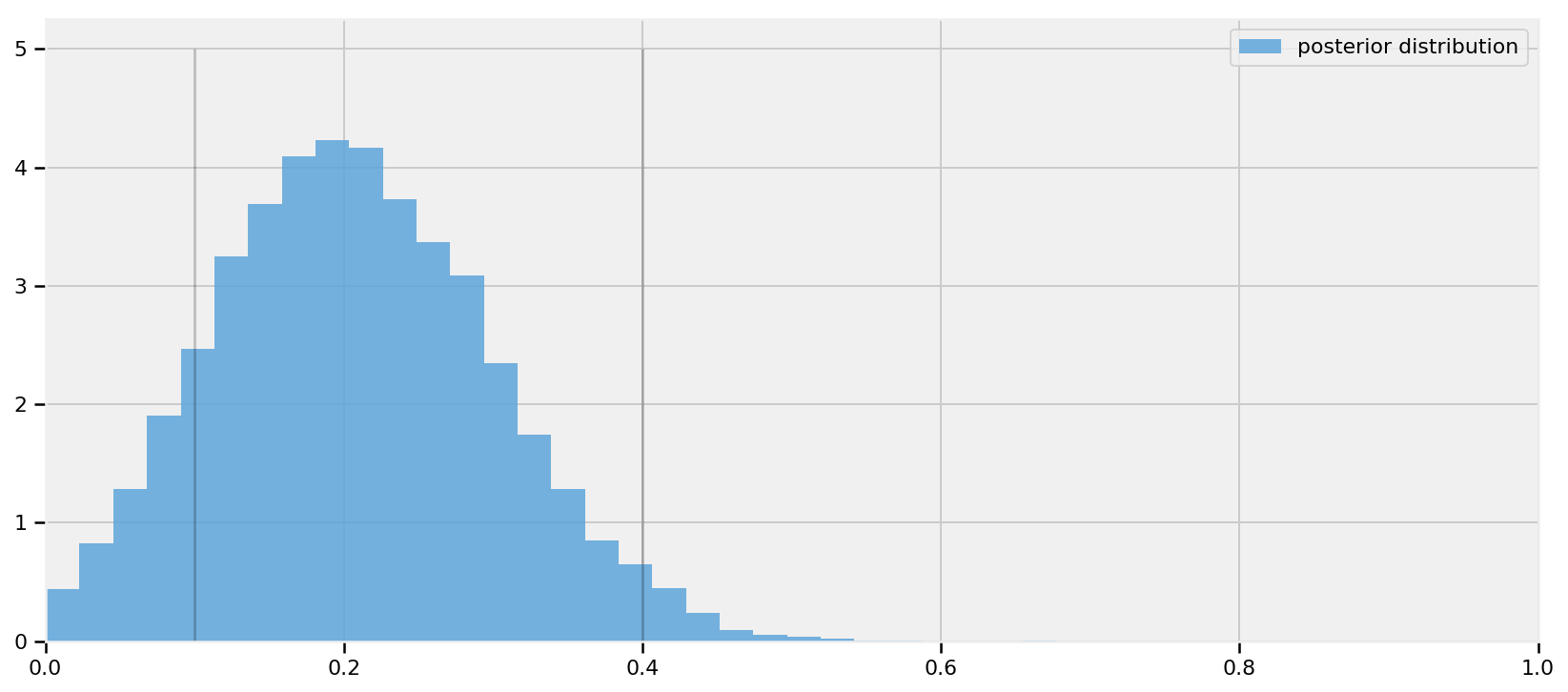
执行TF图以从后验采样
# This cell may take 5 minutes in Graph Mode evaluate(init_g) evaluate(init_l) [posterior_skewed_p_,kernel_results_] = evaluate([posterior_skewed_p,kernel_results])
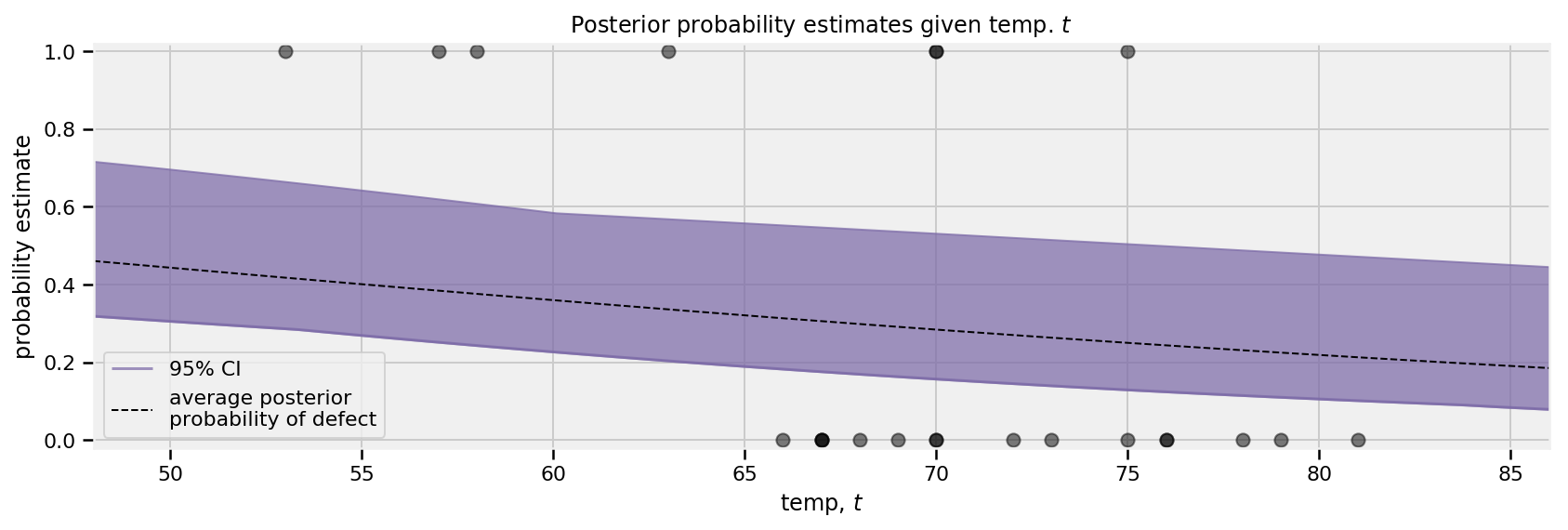
plt.figure(figsize(12.5, 3.5)) np.set_printoptions(precision=3, suppress=True) challenger_data_ = np.genfromtxt("challenger_data.csv", skip_header=1, usecols=[1, 2], missing_values="NA", delimiter=",") #drop the NA values challenger_data_ = challenger_data_[~np.isnan(challenger_data_[:, 1])]
#plot it, as a function of tempature (the first column) print("温度 (F), O型环是否损坏?") print(challenger_data_)
plt.scatter(challenger_data_[:, 0], challenger_data_[:, 1], s=75, color="k", alpha=0.5) plt.yticks([0, 1]) plt.ylabel("Damage Incident?") plt.xlabel("Outside temperature (Fahrenheit)") plt.title("Defects of the Space Shuttle O-Rings vs temperature")
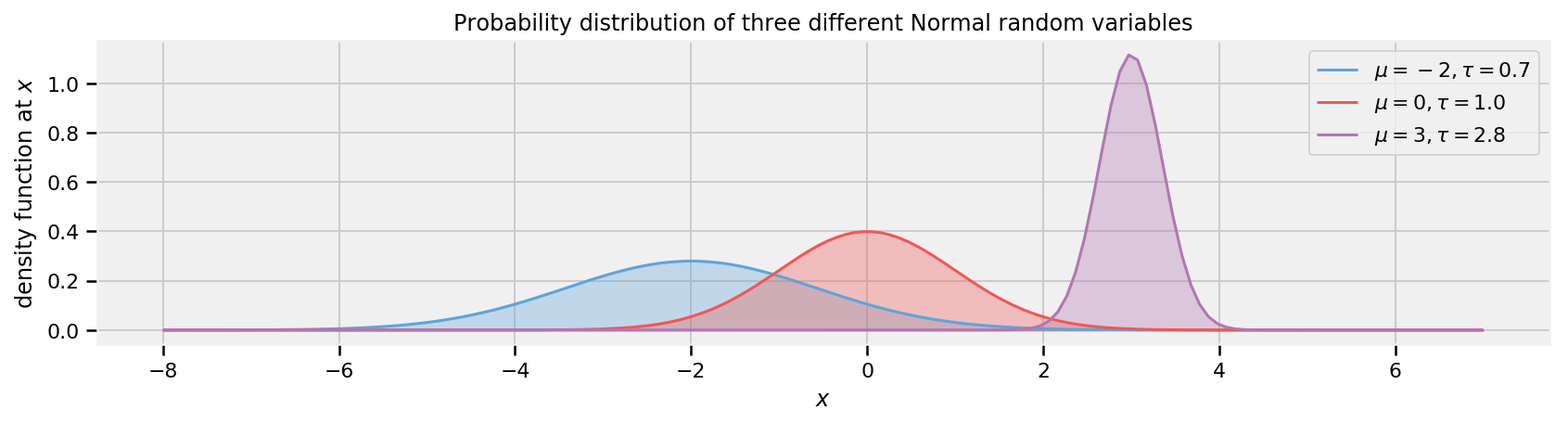
plt.legend(loc=r"upper right") plt.xlabel(r"$x$") plt.ylabel(r"density function at$x$") plt.title(r"Probability distribution of three different Normal random variables")
defchallenger_joint_log_prob(D, temperature_, alpha, beta): """ 联合对数概率优化函数。 Args: D: 来自挑战者灾难的数据表示存在或不存在缺陷 temperature_: 来自挑战者灾难的数据,特别是观察是否存在缺陷的温度 alpha: one of the inputs of the HMC beta: one of the inputs of the HMC Returns: Joint log probability optimization function. """ rv_alpha = tfd.Normal(loc=0., scale=1000.) rv_beta = tfd.Normal(loc=0., scale=1000.)
# make this into a logit logistic_p = 1.0/(1. + tf.exp(beta * tf.to_float(temperature_) + alpha)) rv_observed = tfd.Bernoulli(probs=logistic_p) return ( rv_alpha.log_prob(alpha) + rv_beta.log_prob(beta) + tf.reduce_sum(rv_observed.log_prob(D)) )
# Since HMC operates over unconstrained space, we need to transform the # samples so they live in real-space. # Alpha is 100x of beta approximately, so apply Affine scalar bijector # to multiply the unconstrained alpha by 100 to get back to # the Challenger problem space unconstraining_bijectors = [ tfp.bijectors.AffineScalar(100.), tfp.bijectors.Identity() ]
# Define a closure over our joint_log_prob. unnormalized_posterior_log_prob = lambda *args: challenger_joint_log_prob(D, temperature_, *args)
# Initialize the step_size. (It will be automatically adapted.) with tf.variable_scope(tf.get_variable_scope(), reuse=tf.AUTO_REUSE): step_size = tf.get_variable( name='step_size', initializer=tf.constant(0.01, dtype=tf.float32), trainable=False, use_resource=True )
plt.xlim(0.98, 1) plt.hist(prob_31_, bins=10, density=True, histtype='stepfilled') plt.title("Posterior distribution of probability of defect, given$t = 31$") plt.xlabel("probability of defect occurring in O-ring")
simulations_ = bernoulli_sim_samples_ print("Number of simulations: ", simulations_.shape[0]) print("Number data points per simulation: ", simulations_.shape[1])
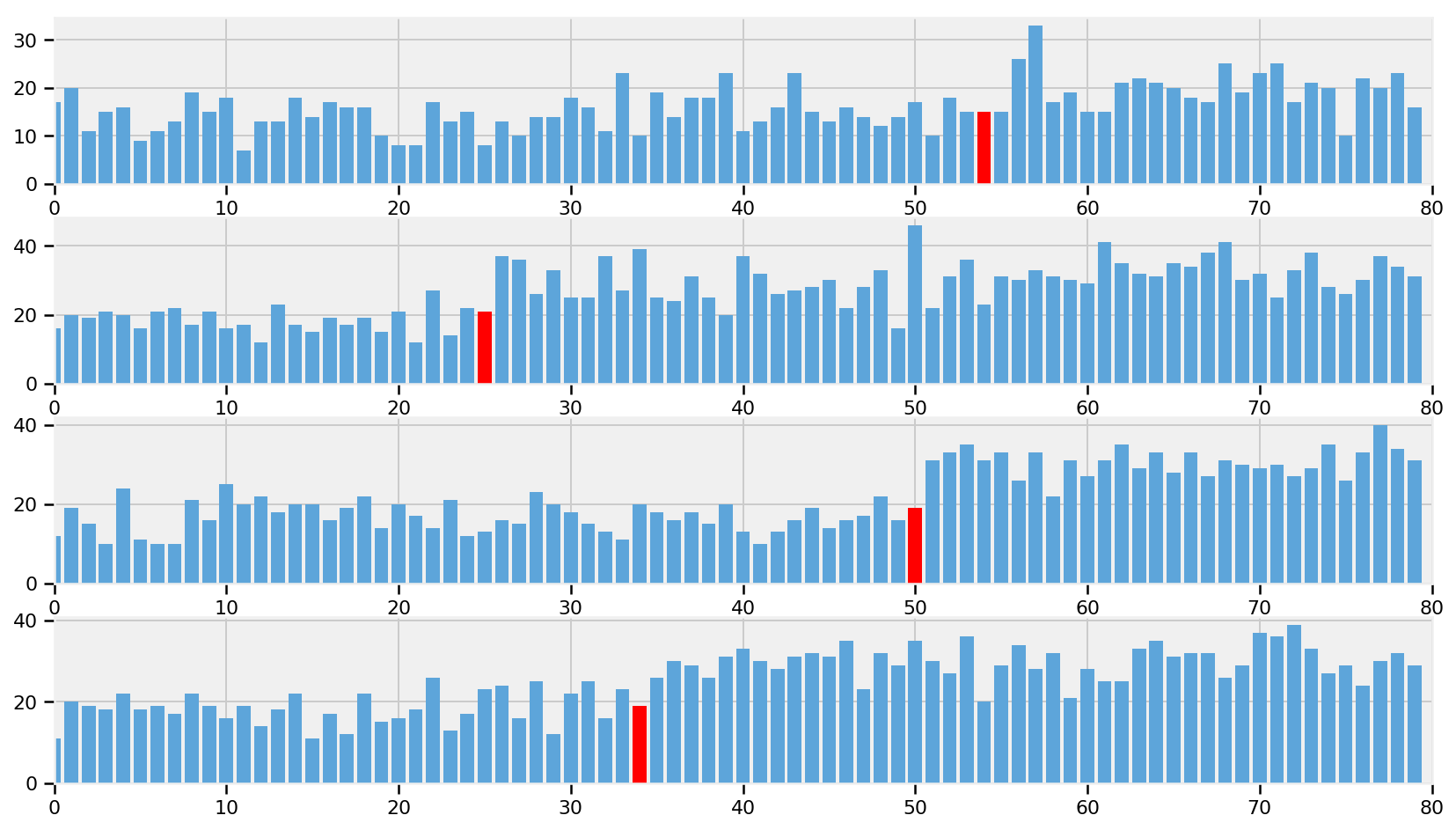
plt.figure(figsize(12.5, 12)) plt.title("Simulated dataset using posterior parameters") for i inrange(4): ax = plt.subplot(4, 1, i+1) plt.scatter(temperature_, simulations_[1000*i, :], color="k", s=50, alpha=0.6)
Number of simulations: 10000
Number data points per simulation: 23
defseparation_plot( p, y, **kwargs ): """ This function creates a separation plot for logistic and probit classification. See http://mdwardlab.com/sites/default/files/GreenhillWardSacks.pdf p: 比例/概率可以是表示M个模型的n×M矩阵。 y: 0-1响应变量。 """ assert p.shape[0] == y.shape[0], "p.shape[0] != y.shape[0]" n = p.shape[0]
try: M = p.shape[1] except: p = p.reshape( n, 1 ) M = p.shape[1]
colors_bmh = np.array( ["#eeeeee", "#348ABD"] )
fig = plt.figure( ) for i inrange(M): ax = fig.add_subplot(M, 1, i+1) ix = np.argsort( p[:,i] ) #plot the different bars bars = ax.bar( np.arange(n), np.ones(n), width=1., color = colors_bmh[ y[ix].astype(int) ], edgecolor = 'none') ax.plot( np.arange(n+1), np.append(p[ix,i], p[ix,i][-1]), "k", linewidth = 1.,drawstyle="steps-post" ) #create expected value bar. ax.vlines( [(1-p[ix,i]).sum()], [0], [1] ) plt.xlim( 0, n) plt.tight_layout() return
In the random model, we can see that as the probability increases
there is no clustering of defects to the right-hand side. Similarly for
the constant model.
In the perfect model, the probability line is not well shown, as it
is stuck to the bottom and top of the figure. Of course the perfect
model is only for demonstration, and we cannot infer any scientific
inference from it.
Exercises
1 Try putting in extreme values for our observations in the cheating
example. What happens if we observe 25 affirmative responses? 10?
50?
#type your code here.
2 Try plotting\(\alpha\)samples
versus\(\beta\)samples. Why might the
resulting plot look like this?
#type your code here. plt.figure(figsize(12.5, 4))
plt.scatter(alpha_samples_, beta_samples_, alpha=0.1) plt.title("Why does the plot look like this?") plt.xlabel(r"$\alpha$") plt.ylabel(r"$\beta$")
References
[1] Dalal, Fowlkes and Hoadley (1989),JASA, 84, 945-957.
[3] Gelman, Andrew. "Philosophy and the practice of Bayesian
statistics." British Journal of Mathematical and Statistical Psychology.
(2012): n. page. Web. 2 Apr. 2013.
[4] Greenhill, Brian, Michael D. Ward, and Audrey Sacks. "The
Separation Plot: A New Visual Method for Evaluating the Fit of Binary
Models." American Journal of Political Science. 55.No.4 (2011): n. page.
Web. 2 Apr. 2013.